AI agents are different from traditional workloads. A scheduled pipeline runs the same query every night. A microservice calls the same API with the same parameters. You can predict what they’ll do and scope their access tightly.
AI agents don’t work that way. They reason, interpret, and decide at runtime. They can be manipulated through prompt injection, take unintended actions from vague prompts, or simply make poor judgment calls. An agent with broad access to your data warehouse isn’t just a workload, it’s an autonomous actor with the ability to surprise you.
This changes the access control equation entirely.
Workload Identity Isn’t Enough for Agents
The industry has made real progress on workload identity. Service accounts, managed identities, identity federation, and frameworks like SPIFFE have laid the groundwork, and solutions exist to help put them into practice. But even modern workload identity has a gap when it comes to agents.
Workload identity tells you what is making a request. For traditional workloads, that’s usually sufficient. But AI agents act on behalf of different users, processing different prompts, with different intents. The same agent might query a data warehouse for one user’s regional sales data and, moments later, attempt to update a CRM record for another. Worse, it might be tricked into accessing data the prompting user was never meant to see.
Workload identity treats all of these invocations identically. You’re forced to provision access for the broadest possible use case, giving every user the same effective permissions and giving the agent enough rope to cause real damage if it misbehaves.
Effective Access Policies: Scoping Agents by User Context
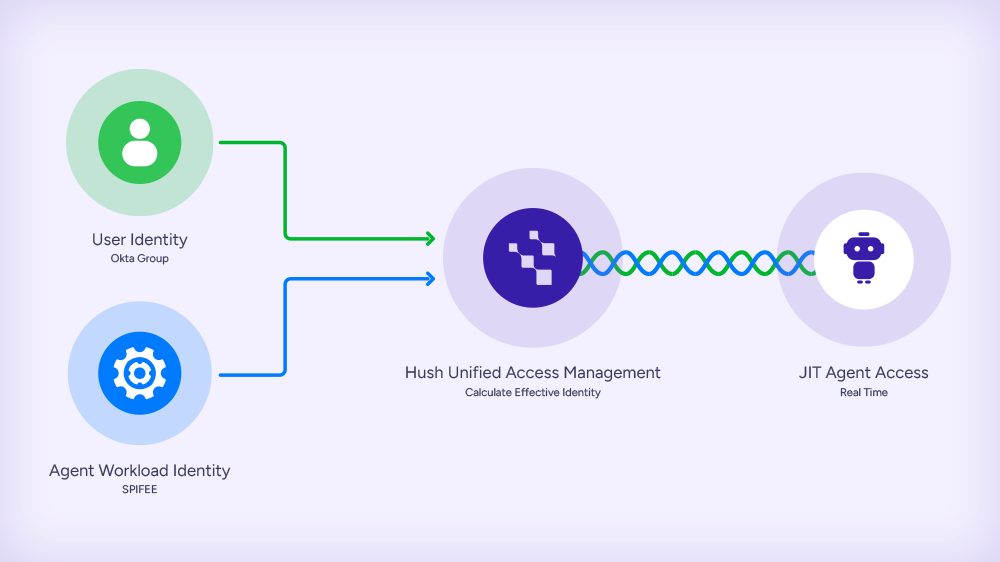
The solution is what we call an effective access policy: an access decision resolved from the combination of the agent’s verified identity and the authenticated user’s identity claims.
Agent identity establishes the first plane, confirming which agent is making the request through cloud-native identity, SPIFFE attestation, or other mechanisms.
User identity establishes the second. When a user interacts with an agent, their IdP-issued token carries their identity, group memberships, and roles.
Policy resolution evaluates both together, selecting the privilege set that matches the effective identity. The agent’s access dynamically adjusts based on who is driving it.
This means a sales analyst chatting with an agent gets scoped access to their region’s data, even if the agent could reach the entire warehouse. A finance lead using the same agent gets broader access, because their claims justify it. And if the agent is manipulated into an unexpected query, the damage is bound by the current user’s permissions, not the agent’s total capability.
The user’s identity becomes a natural blast radius limiter.
What This Looks Like in Practice
Consider an AI agent that helps teams interact with Snowflake, Salesforce, and internal APIs through natural language:
A regional analyst asks for sales numbers. The agent’s identity is verified, the analyst’s IdP token identifies them as “EMEA-sales-ops.” The effective policy scopes Snowflake access to EMEA data only, even if the agent is tricked into querying global data.
An account executive asks the agent to update a deal. Same agent, but the user’s token carries “sales-AE” claims. The effective policy grants write access to their own Salesforce opportunities, not the full CRM.
Automated pipeline, no user. The same underlying service runs a scheduled job without a user session. The workload-only policy applies, broad access for a known, predictable task.
The agent never implements this logic. The policy engine evaluates both identity planes and provisions the right credentials just in time.
How Hush Security Approaches This
At Hush Security, we’ve built effective access policies into our Unified Access Management platform. The platform uses SPIFFE for workload attestation, which offers the strongest cryptographic foundation for agent identity, especially in multi-cloud environments, and then it validates IdP-issued tokens for user identity. The policy resolves at runtime, and Hush provisions scoped, just-in-time credentials automatically.
The agent gets exactly the access the current user should have, and nothing more.
How AI-powered security is solving yesterday’s problem while tomorrow’s is already here.
When Anthropic announced Claude Code’s security capabilities, the reaction across the industry was immediate and justified. AI that can scan your codebase, identify vulnerabilities, and suggest fixes in real time is a genuine leap forward. For teams that have spent years manually triaging CVEs and chasing injection flaws across sprawling codebases, this feels like the moment the tide finally turns.
And in many ways, it is.
But there’s a question worth sitting with: when AI locks down the code layer, where does the risk go?
The answer is uncomfortable – and mostly ignored.
The Progress Is Real. So Is the Blind Spot.
Let’s give credit where it’s due. Application security has historically been a game of whack-a-mole. Developers ship fast. Vulnerabilities slip through. Security teams scramble to patch, prioritize, and communicate risk to stakeholders who want everything fixed yesterday. Static analysis tools helped, but they were slow, noisy, and required expertise to interpret. Penetration testing was episodic. Bug bounties were reactive.
AI changes the economics of all of this. Continuous, intelligent scanning embedded in the development workflow means vulnerabilities get caught earlier, fixed faster, and with less human overhead. Injection flaws, misconfigurations, dependency risks – the class of problems that have dominated the AppSec conversation for decades are becoming increasingly addressable through automation.
This is meaningful progress. Fewer CVEs reaching production is unambiguously good.
But security doesn’t operate in a vacuum. When you close one door, attackers don’t give up – they find the next one. And right now, while the industry’s attention is concentrated on making code safer, a different attack surface is quietly expanding.
The Attack Surface Is Shifting – Into Identity
Here’s what’s actually happening underneath the surface of the AI-driven development boom.
Every AI agent, every automated pipeline, every microservice, every cloud workload needs to authenticate somewhere. It needs to talk to a database, call an API, read from storage, write to a queue. And to do any of that, it needs credentials.
In most enterprises today, those credentials are static secrets – API keys, service account tokens, long-lived passwords – stored in vaults, hardcoded in repos, or passed around in environment variables across teams and systems. This was already a fragile approach before AI entered the picture. Now, as organizations race to deploy AI agents at scale, the problem is compounding faster than most security teams can track.
Consider what AI-native development actually produces at the infrastructure level:
More services. More integrations. More automated pipelines. More workloads spinning up and down at runtime. Each one requiring access. Each one representing a potential identity that needs to be managed, monitored, and governed.
The code is getting cleaner. The identity layer is getting messier.
Three Shifts Nobody Is Talking About Loudly Enough
From CVEs to credentials. The vulnerability classes that have dominated security discourse for years – SQL injection, XSS, buffer overflows – are precisely the things AI is best positioned to catch. But the credentials that authenticate the services running that cleaner code? Those are largely outside the scope of AppSec tooling. A perfectly patched application running on an over-privileged service account with a two-year-old API key is still a serious risk. The surface has shifted, not shrunk.
From human to non-human identity. For most of security’s history, identity meant users. You managed employees, contractors, admins. You enforced MFA, monitored login anomalies, revoked access when people left. That paradigm is breaking down. In modern cloud environments, non-human identities – service accounts, machine tokens, OAuth credentials, AI agents – already outnumber human users by orders of magnitude in most organizations. And they’re growing faster. Every new AI agent means dozens(!) of new identities. Every new integration is a new credential. The attack surface is predominantly non-human, and most security architectures were built for a world where it wasn’t.
From static to dynamic. Traditional secrets management was built on a simple assumption: store the credential securely, rotate it periodically, and you’ve done your job. That model made sense when environments were relatively stable. It doesn’t make sense in a world of ephemeral workloads, containerized microservices, and AI agents that spin up, complete a task, and disappear within minutes. A static secret issued to a workload that lives for 30 seconds doesn’t need to be valid for 90 days. But in most organizations, it is – because the infrastructure to do anything different doesn’t exist.
Why the Vault and Scanners are Not Enough
Secrets managers have been the industry default for non-human identity management for good reason. They’re better than hardcoded credentials. They provide centralized storage, access controls, and rotation capabilities. For a long time, they were enough.
But the enterprise environment has outgrown them in ways that are now impossible to ignore.
Vaults are excellent at storing secrets. They’re not designed to answer the questions that matter most in a dynamic, AI-driven environment:
Where is this credential actually being used?
Which workload is consuming it right now?
Is it scoped to the minimum permissions needed for this specific task?
Has it been sitting dormant for six months because the service it was created for was deprecated and no one noticed?
Discovery tooling has emerged to fill part of this gap – scanning environments for unmanaged credentials, mapping blast radius, surfacing hardcoded secrets in codebases. These tools are valuable. But they’re diagnostic, not prescriptive. They tell you what the mess looks like. They don’t fix it, and they don’t prevent the next one.
The “secretless” architecture vision attempts to eliminate the problem at the root – replacing credentials entirely with identity-based access that doesn’t require a secret to be stored or transmitted. It’s the right destination. But it requires deep re-architecture, significant investment, and migration timelines that most enterprises – especially those in heavily regulated industries with complex legacy environments – simply can’t absorb all at once.
Which leaves most organizations caught between approaches, piecing together a vault, a discovery tool, and some governance layer, and hoping the combination is sufficient.
It usually isn’t.
What the Agentic Era Actually Demands
The deployment of AI agents isn’t a future scenario. It’s happening now, in production, at Fortune 500 companies across every industry. And the security implications are arriving faster than the frameworks to address them.
An AI agent is, from an identity and access perspective, a workload like any other – except it tends to require broader access, operate more autonomously, and interact with more systems than a traditional service. It might need to read from a database, call external APIs, write to a content management system, trigger downstream workflows, and authenticate to multiple internal services, all within a single task execution.
If that agent is operating with a long-lived credential scoped with more permissions than it needs – which is the current reality in most organizations – the blast radius of a compromise isn’t just the agent itself. It’s every system the agent’s credentials can reach.
This isn’t hypothetical. The attack patterns are already emerging. Credential theft targeting automated pipelines. Privilege escalation through over-permissioned service accounts. Lateral movement through interconnected AI workflows. The techniques aren’t new. The scale and speed at which they can be executed against a fragmented, poorly governed non-human identity landscape is.
What the agentic era demands isn’t a better vault or a smarter scanner. It demands a fundamental rethinking of how access is granted, governed, and revoked for non-human identities at runtime.
Specifically, it demands just-in-time access – where credentials are issued for the duration of a specific task, scoped to the minimum permissions required, and automatically revoked when the task completes. No long-lived tokens. No standing privileges. No credentials that outlive the workload they were created for.
It demands unified visibility – a single control plane that spans cloud, hybrid, and on-premise environments, giving security teams a real-time view of every non-human identity, what it has access to, and what it’s actually doing.
And it demands a path that works now – not after a multi-year re-architecture project. Organizations need to be able to reduce risk against their existing infrastructure while building toward a least-privilege, identity-based future. These goals aren’t mutually exclusive, but achieving both requires a platform designed with that tension in mind.
The Winners Will Own the Control Plane
The non-human identity market is crowded and consolidating fast. Vault vendors are expanding their feature sets. Discovery tools are adding governance layers. AppSec platforms are moving into runtime. Everyone is racing toward the middle.
The vendors who win this space won’t be the ones with the best scanner or the smartest vault. They’ll be the ones who unify discovery, storage, and governance into a single control plane – replacing static secrets with just-in-time, identity-based access, across cloud, hybrid, and the legacy systems everyone knows exist but no one wants to talk about.
That’s not a minor product improvement. It’s a different architectural thesis. And the enterprises that figure this out early – that start treating non-human identity with the same rigor they’ve applied to application security – will be the ones operating from a position of strength as the agentic era matures.
The Target Hasn’t Disappeared
AI-powered application security is a genuine advancement. The code layer is getting safer. CVEs are getting caught earlier. Injection flaws that have plagued development teams for decades are increasingly solvable through automation.
But the attack surface hasn’t shrunk. It’s shifted – into workload identity and runtime access. Into the credentials authenticating the AI agents, microservices, and automated pipelines that now form the operational backbone of modern enterprises.
Less vulnerable code. More long-lived credentials. Fewer injection flaws. More over-privileged service accounts. Better applications. More unmonitored AI agents with unchecked access.
The security architecture that got us here was built for a world of human users, monolithic applications, and static environments. It’s not the architecture we need for a world of AI agents, ephemeral workloads, and dynamic, multi-cloud infrastructure.
The shift is already happening. The question is whether security teams will recognize where the new perimeter actually is – and build toward it – before the attackers make it impossible to ignore.
Over the past decade, cloud adoption and API-first architectures have exploded. Every microservice, CI/CD pipeline, third-party integration, and automation script requires credentials to function. Today’s organizations manage tens of thousands of API keys, service account tokens, certificates, and secrets, collectively known as Non-Human Identities (NHIs).
Unlike human identities, NHIs proliferate unchecked, rarely expire, and often hold excessive privileges. When the GitGuard leak exposed over 10 million secrets on GitHub, and when CircleCI’s breach compromised thousands of customer secrets, the industry woke up to a critical gap: we had no systematic way to manage, monitor, or secure non-human identities at scale.
This realization spawned a new category of NHI security tools. But three years in, organizations are still experiencing breaches. The problem? These tools aren’t solving the actual problem.
Why Current NHI Tools Are Failing
1. Limited Visibility: Log-Based Detection Misses the Full Picture
Most NHI tools rely on scanning logs, code repositories, and configuration files to detect exposed secrets. This approach has fundamental limitations:
Integration-dependent blind spots – They only see what they’re integrated with. Secrets in proprietary systems, legacy applications, or new SaaS tools remain invisible.
Point-in-time snapshots – Log scanning provides historical data, not real-time awareness of active secrets in production.
Incomplete coverage requires tool sprawl – Organizations deploy multiple complementary tools (repo scanners, log analyzers, CSPM tools) just to achieve partial visibility, creating fragmented insights and operational complexity.
The result: You’re blind to a significant portion of your NHI attack surface.
2. Static Risk Posture: Not Risk-Based on Reality
Current tools assess risk based on static configurations, whether a secret is overprivileged, improperly scoped, or detected in a repository. But they lack runtime context:
No visibility into actual usage – Is this API key actively being used? When was it last called? From where?
No understanding of exploitability – Which secrets, if compromised, could actually cause damage versus dormant credentials with no real-world impact?
No prioritization based on business context – Not all exposed secrets carry equal risk, but tools treat them uniformly, flooding teams with thousands of “critical” findings.
The result: Security teams drown in alerts they can’t prioritize, while truly critical risks hide in the noise.
3. No Effective Remediation: Jira Tickets Aren’t Security
Perhaps the most glaring failure: every existing tool considers opening a Jira ticket as “remediation.”
Here’s what actually happens:
Tool detects an exposed secret
Creates a ticket assigned to a developer
Developer is already buried in work
Ticket sits in backlog for weeks or months
Secret remains exposed and exploitable
This isn’t remediation, it’s offloading responsibility and hoping someone eventually gets to it. Meanwhile:
Developers lack context to prioritize the ticket
Manual secret rotation is complex and error-prone
Teams fear breaking production, so they delay
The “remediated” number in dashboards is a fiction
The result: Organizations have impressive detection metrics but unchanged security outcomes.
4. The Treadmill Problem: Creation Outpaces Remediation
Even when teams heroically remediate dozens of exposed secrets, hundreds more are being created simultaneously:
Developers spin up new services with hardcoded credentials
CI/CD pipelines generate new API keys
Third-party integrations add more service accounts
Shadow IT proliferates unmanaged secrets
You’re running on a treadmill that’s speeding up. No matter how fast you remediate, the backlog grows. This approach cannot win long-term, it’s mathematically unsustainable.
The result: The NHI problem compounds over time despite significant investment in security tools.
So What Are Teams Ending Up Doing
Recognizing these gaps, organizations attempt to solve NHI security by combining multiple tools:
NHI scanners – These tools provide limited visibility, primarily detecting only what they are directly connected to. They rely on log ingestion and can become costly for customers at scale.
Vault or Secrets Manager – Almost every organization has one (or multiple), but these are storage solutions, not security tools. They’re safes where you store secrets; they don’t tell you which secrets are exposed, overprivileged, or actively exploited.
CSPM tools – Offer limited visibility mostly for major cloud providers (AWS, GCP, Azure) and a limited set of supported applications, with no remediation capabilities, just more alerts to manually triage.
But this Frankenstein approach creates new problems:
Fragmented visibility – Each tool shows a different piece of the puzzle; no unified view of your actual NHI risk
Alert fatigue – Multiple tools generating overlapping alerts with no centralized prioritization
No coordinated remediation – Each tool operates in isolation; rotating a secret in Vault doesn’t update the scanner’s findings
Operational overhead – Security teams spend more time managing tools than managing risk
Companies experiencing major NHI-related breaches were already using these tools. Despite deploying scanners, vaults, and CSPM platforms, their non-human identities remained exploitable. Detection without prevention leaves the door wide open.
A New Approach Is Required
The fundamental problem is that existing tools treat NHI security as a detection problem when it’s actually a governance and access control problem.
We don’t solve human identity security with scanning tools. We solve it with centralized identity governance platforms that enforce least-privilege access, monitor usage in real-time, and automate lifecycle management.
The same principles apply to non-human identities:
What’s Needed: A Unified NHI Governance Platform
Centralized Control Across All NHI Types
API keys, service accounts, OAuth tokens, certificates, database credentials—managed in one platform
Works across cloud providers (AWS, GCP, Azure), SaaS applications, on-prem systems, and custom infrastructure
Real-Time Runtime Visibility
See which secrets are actively used, when, and by what
Understand actual exploitability and business impact
Risk scoring based on live data, not static configurations
Policy-Based Governance
Apply cloud IAM security principles (least privilege, ephemeral access, policy enforcement) to ALL non-human identities
Centralized policy engine that works uniformly across your entire tech stack
Built-In Remediation
Don’t create tickets, fix the problem automatically
Existing NHI tools are failing because they’re solving the symptom and not curing the disease. They’re detection engines in a world that needs governance platforms.
Organizations need a centralized NHI governance and control platform, one that applies proven identity security principles across all non-human access, finds and remediates risks automatically, and scales with the explosive growth of machine identities.
It’s time to stop detecting the problem and start preventing it.
AI agents are rapidly moving from experimental tools to first-class actors inside production environments. They call LLM APIs, orchestrate workflows through MCP servers query databases like Postgres and Snowflake, and trigger actions in third‑party SaaS platforms such as Stripe.
But from a security perspective, there’s an uncomfortable truth most organizations haven’t fully confronted yet:
AI agents are operating with the same static credentials model we already know is broken-only now at machine speed and machine scale.
For CISOs, this isn’t just another secrets management problem. It’s a new, amplified data‑exfiltration risk surface.
The Hidden Risk: AI Agents Inherit the Worst of Static Credentials
Today, most AI agents authenticate exactly like legacy services:
Long‑lived API keys for LLM providers
Static database credentials for Postgres or Snowflake
Hard‑coded SaaS tokens for Stripe or internal APIs
Broad permissions granted “just in case” the agent needs them
From a risk standpoint, this creates a perfect storm:
No identity context – Credentials don’t know who is using them or why
No execution awareness – Access looks the same whether it’s a valid task or a malicious prompt
No blast‑radius control – A single leaked key can unlock massive datasets
No runtime enforcement – Once issued, the key works everywhere, all the time
When an AI agent is compromised-through prompt injection, model manipulation, supply‑chain risk, or simple misconfiguration-the organization has no meaningful way to contain the damage.
This is how silent data exfiltration happens.
Why Traditional Controls Fail Against Agentic Access
Security teams often try to compensate by layering controls around static credentials:
Network restrictions
Token rotation policies
Monitoring and anomaly detection
These help-but they don’t solve the core issue.
Static credentials are non‑contextual by design. They can’t express:
Which agent is calling the service
What task the agent is executing
What data should be accessible right now
Whether the request violates business or security intent
For human identities, we solved this years ago with identity‑aware access, conditional policies, and least privilege.
For AI agents, most organizations are still stuck in 2010.
The Shift: From Secrets to Policy‑Based Agent Identity
Preventing data exfiltration by AI agents requires a fundamental shift:
Stop authenticating agents with static secrets. Start authorizing them with policy‑based identity.
In a policy‑based model:
AI agents authenticate using a strong, verifiable runtime identity
Access is granted dynamically, not pre‑embedded in code
Every request is evaluated against real‑time policy
Permissions are scoped to task, resource, and time
Instead of asking:
“Does this API key look valid?”
The system asks:
“Should this agent, performing this action, access this resource right now?”
That question is the difference between control and blind trust.
Applying Policy‑Based Access to LLMs, MCP, and SaaS
Policy‑based identity isn’t theoretical-it applies directly to the systems AI agents already touch.
LLM Services
Limit which models an agent can access
Restrict prompt and response scopes
Enforce usage boundaries per task or environment
Prevent cross‑tenant or cross‑context leakage
MCP and Internal Services
Bind agent identity to specific workflows
Prevent lateral movement between services
Enforce service‑to‑service least privilege dynamically
Databases and Data Platforms
Grant just‑in‑time access to Postgres or Snowflake
Restrict queries to approved schemas or datasets
Automatically revoke access when the task completes
Third‑Party SaaS (e.g., Stripe)
Scope actions to specific operations (read vs. write vs. execute)
Eliminate long‑lived tokens embedded in agent logic
The result: even if an agent is manipulated, its ability to exfiltrate data is structurally constrained.
Why This Matters to CISOs Now
AI agents change the economics of risk.
They:
Operate continuously
Act autonomously
Chain multiple systems together
Access high‑value data at scale
A single compromised agent can do more damage, faster, than dozens of traditional workloads and services.
From a CISO perspective, this raises hard questions:
Can we prove which agent accessed sensitive data?
Can we enforce least privilege at runtime-not design time?
Can we contain an incident without taking systems offline?
Can we show auditors that agent access is governed and intentional?
Static credentials cannot answer these questions.
Policy‑based identity can.
The Solution: How Hush Enables Secure Agentic Access
Preventing data exfiltration by AI agents requires more than better secrets hygiene. It requires eliminating secrets as the primary control plane altogether.
Hush enables organizations to shift AI agents from secret-based access to policy-based identity, fundamentally changing how agentic access is granted, evaluated, and enforced at runtime.
Instead of embedding long-lived API keys, tokens, or database credentials into agent logic, Hush:
Establishes a strong runtime identity for each AI agent
Replaces static secrets with just-in-time, policy-evaluated access
Authorizes every request based on who the agent is, what it is doing, and what it should access
This shift is critical for stopping data exfiltration.
With policy-based access enforced by Hush:
AI agents never hold standing credentials that can be leaked, reused, or abused
Access is narrowly scoped to approved actions, data sets, and services
Permissions automatically expire when the task or context ends
Compromised or manipulated agents are structurally limited in what data they can reach
By removing static secrets from the equation and enforcing identity-driven, runtime policy, Hush turns AI agents from an uncontrolled data exfiltration risk into governed, auditable non-human identities.
This is not an incremental improvement.
It is the difference between hoping an AI agent behaves – and ensuring it cannot cause harm even if it doesn’t.
In the first half of 2024 alone, the cybersecurity landscape was rocked by high-profile incidents, including the Snowflake data breach and major compromises at Microsoft, that shared a common, devastating thread: stolen credentials and compromised secrets. These weren’t sophisticated “zero-day” exploits of technical flaws; they were attackers simply “logging in” using valid, but stolen, identities to compromise entire organizations. For years, the industry has preached “cyber hygiene”, the digital equivalent of brushing your teeth: use strong passwords, patch your systems, and don’t click suspicious links. While essential, hygiene is no longer enough to serve as a strategy.
The problem with the “cyber hygiene” metaphor is that it suggests a simple pass or fail, either your credentials are clean and you’re safe, or they’re dirty and you’re exposed. In reality, keys and tokens can be handled “perfectly”: stored in a vault, scoped carefully, rotated on schedule, and still end up in the hands of an attacker. Recent incidents, including the Snowflake and Microsoft-related breaches, reinforced a hard truth: attackers don’t always need to exploit vulnerabilities if they can just log in with valid credentials.
The Speed of Development Has Outpaced Hygiene
Today’s “ship-it-yesterday” development culture doesn’t give security teams the luxury of relying solely on best practices and good hygiene. As organizations race to adopt new technologies, the basics can get buried under delivery pressure. In a world of microservices, CI/CD pipelines, and now agentic AI, the perimeter is no longer a fixed wall you can keep “clean.”
If your strategy is built only on hygiene and best practice, your organization can collapse the moment a developer hardcodes a secret, an employee falls for a sophisticated phishing attack, or an OAuth key in a third-party SaaS app is compromised. In today’s complex environments, security teams need a breach-ready approach: harden posture, tighten exposure, and assume compromise, then build controls that contain blast radius and keep you operating when it happens.
What “Building for Breach” Actually Means
If we accept that compromise is inevitable, that credentials will be stolen, insiders will exist, and trust boundaries will be crossed, the security model shifts entirely.
This shift matters even more now because automation and agentic AI are exploding the number of non-human identities, secrets, AI agents, and MCP connections across every environment. What used to be a manageable set of service accounts and API keys is turning into a massive, fast-changing web of machine access. That growth is quietly expanding the attack surface, yet this vector still doesn’t get the attention, visibility, or shared understanding it deserves, especially when it comes to how easily one compromised identity can cascade into an organization-wide breach.
Minimize/Reduce Risk Where and When Possible
In the identity security world, the leading attack vector is still secret-based access, API keys, tokens, shared credentials, and long-lived secrets that attackers can steal and reuse. The good news is this risk can be minimized to near-elimination by moving from secrets-based access to identity-based access. In practice, that means extending the machine identity model the major cloud providers already use internally to everything else in your environment: internal services, SaaS tools, pipelines, agents, and MCP servers. With a battle-tested framework like SPIFFE, workloads get strong, verifiable identities and short-lived credentials, so access is granted based on identity and policy instead of static secrets.
This shift strips a huge part of the security burden away from developers and DevOps, who shouldn’t be in the business of handling and protecting long-lived secrets. Instead, security teams regain control through centralized policy, consistent identity issuance, and enforcement that holds even when something is compromised.
Building for breach means assuming one of those identities will be compromised and designing so it doesn’t become a full-org incident: remove long-lived secrets, eliminate standing access, enforce right-sized and just-in-time permissions at runtime, and make actions fully attributable so you can detect, contain, and keep your business operating when compromise happens.
Cyber hygiene is the starting line, not the strategy. In a world where attackers don’t break in, they log in, security must shift from the impossible goal of absolute prevention to the essential reality of breach-ready resilience, building a system that assumes compromise and is engineered to survive it.
When applications need to talk to each other, they face a fundamental challenge: how does one system prove it’s legitimate when accessing another? For decades, we’ve relied on secrets - passwords, keys, and tokens - to solve this problem. But as our infrastructure has grown more complex and distributed, these approaches have shown their limitations. Let’s trace the evolution of machine-to-machine authentication and explore where we’re headed.
The Beginning: Early Shared Secrets
In early distributed computing, authentication was simple but insecure, relying on hardcoded passwords or shared secrets in configuration files. Credentials were often stored in plaintext, checked into version control, and widely shared. This simplicity made the method popular despite the clear security flaw: access to the codebase or environment meant access to all secrets.
The Rise of API Keys
As the web services era dawned in the 1990s and 2000s, API keys emerged as the dominant pattern for machine authentication. Rather than usernames and passwords, services generated long random strings - API keys - that applications would include in their HTTP requests, typically as headers or query parameters.
The API key model quickly became ubiquitous. Google Maps API, AWS, Stripe, Twilio, SendGrid, GitHub, and countless other services adopted API keys as their primary authentication mechanism.
Why did API keys become so prominent? Several factors drove their adoption:
Simplicity: API keys were easy to generate, distribute, and use. Developers could get started with a new service in minutes.
Language agnostic: Unlike some authentication schemes that required specific libraries or cryptographic capabilities, API keys worked with any HTTP client. A simple string in a header was universally supported.
Revocability: Unlike changing a password that might be shared across services, individual API keys could be revoked without affecting other integrations.
Auditability: Different keys could be issued for different applications or environments, making it easier to track which system was making which calls.
This combination of ease-of-use and operational flexibility made API keys the default choice for API authentication, a position they still hold in many systems today.
The Problem with Static Secrets
Despite their popularity, API keys and other static secrets suffer from fundamental problems that have become increasingly apparent as our systems have scaled.
Secrets sprawl: In a microservices architecture, applications might need dozens or hundreds of different credentials to communicate with various services, databases, and APIs. Each secret must be securely stored, distributed to the right places, and kept synchronized across environments. Managing this sprawl becomes a significant operational burden.
Rotation challenges: Security best practices dictate regular credential rotation, but static secrets make this painful. Changing an API key requires updating every application that uses it, coordinating deployments across teams, and ensuring no downtime during the transition. In practice, many organizations simply don’t rotate credentials as often as they should.
Blast radius: When a static secret is compromised, there’s no inherent limit to how it can be used. An API key stolen today might work for months or years until someone notices and revokes it.
Storage vulnerabilities: Static secrets must be stored somewhere, whether in environment variables, configuration management systems, or secrets vaults. Each storage location represents a potential attack vector.
But perhaps the most fundamental issue is conceptual: static secrets are not identities. An API key tells you that someone possesses a particular string of characters, but it doesn’t tell you who that someone is or why they should have access. There’s no inherent binding between the secret and the workload using it. If an attacker obtains your API key, they can impersonate your application perfectly - the receiving service has no way to distinguish legitimate use from unauthorized access.
This lack of true identity makes it difficult to implement sophisticated security policies. You can’t easily say “this microservice should only be able to call this other service when running in production, from these specific clusters, during business hours” when authentication is just a static string that could be used by anyone, anywhere.
A New Generation of Authentication
Recognizing these limitations, the industry has developed authentication methods that move beyond static secrets toward cryptographically-verifiable identity and dynamic credentials.
Mutual TLS
Mutual TLS (mTLS) represents one of the earliest attempts to move beyond simple secrets. While traditional TLS authenticates the server to the client (ensuring you’re really talking to your bank, not an imposter), mutual TLS adds client authentication - both parties present certificates to prove their identity.
Each service receives an X.509 certificate from a certificate authority (CA), and these certificates contain identity information that can be cryptographically verified. When two services communicate, they exchange certificates, verify signatures, and establish that both parties are who they claim to be.
The advantages are significant. Certificates provide strong cryptographic identity, can’t be easily stolen or replayed, and support automatic rotation. The communication channel itself is encrypted, protecting against eavesdropping. And unlike static secrets, certificates bind identity to cryptographic keys that never leave the service.
However, mTLS introduces operational complexity. Someone must run a certificate authority, manage certificate lifecycles, handle revocation, and ensure certificates are properly distributed to all services. In large deployments with hundreds of microservices, this can become a substantial engineering effort.
OAuth 2.0 Client Credentials Flow
While OAuth 2.0 is primarily used for authorization (such as granting apps access to your data, like your Google Drive), the Client Credentials flow was specifically designed for machine-to-machine scenarios. The flow works like this: An application authenticates to an OAuth authorization server using its client ID and client secret, requesting access to specific resources. The server validates the credentials, checks the requested permissions, and issues a time-limited token (often a JWT) that grants those specific permissions. The application then presents this token when calling other services, avoiding the need to present static credentials with every call.
This architecture provides several benefits. Tokens are short-lived-typically expiring in minutes or hours – dramatically reducing the window of vulnerability if a token is compromised. Tokens can be scoped to specific permissions, implementing the principle of least privilege. The authorization server acts as a central policy enforcement point, making it easier to audit access and revoke permissions. And by separating authentication (proving who you are) from authorization (what you can do), the system becomes more flexible.
Cloud IAM and Instance Identity
Cloud platforms introduced a paradigm shift: what if workload identity could be derived from where the workload runs, rather than from secrets it possesses?
AWS IAM roles, pioneered the secrets-less approach. Instead of using long-lived static keys, an EC2 instance or Lambda is assigned an IAM role, and the AWS platform provides temporary, auto-rotating credentials tied to that role. The application simply asks the platform for its credentials. Google Cloud’s service accounts and Azure’s managed identities operate similarly: applications authenticate using an identity cryptographically bound to the compute instance or container. The platform guarantees that only workloads running in specific locations with specific attributes can obtain credentials for a given identity.
This approach eliminates entire classes of vulnerabilities. There are no static secrets to leak, no credentials in environment variables or configuration files, and no need for complex secret distribution systems - at least for workloads running in the cloud. Identity becomes a property of the workload’s runtime environment, verified by the platform itself.
The limitation, of course, is that this only works within the cloud provider’s ecosystem. A service running on AWS can’t natively use its IAM role to authenticate to a database running in your datacenter or to an external third-party service.
Workload Identity and SPIFFE
The final evolution - and perhaps the most promising - is the emergence of workload identity frameworks that work across any environment. The SPIFFE (Secure Production Identity Framework For Everyone) standard defines how to assign cryptographic identities to workloads based on their attributes, regardless of where they run.
SPIFFE gives each workload a unique ID. The workload’s identity is attested and issued an SVID (SPIFFE Verifiable Identity Document), which cryptographically proves ownership of that identity and comes in the form of either an X.509 certificate or a JWT. The SVID then serves as the identity proof when the workload authenticates with other services. A system called SPIRE (SPIFFE Runtime Environment) manages the issuance and rotation of these identity documents.
SPIFFE’s strength lies in its flexibility, allowing workload identity to be attested through various factors such as the Kubernetes service account, the specific cloud instance, or properties of the container image. SPIRE automatically rotates SVIDs, typically every few hours, providing both the security benefits of short-lived credentials and the operational simplicity of automatic management.
Service mesh platforms like Istio have adopted SPIFFE as their identity layer, automatically handling mTLS between services using SPIFFE identities. This creates a “zero trust” network where every connection is authenticated and encrypted, but without requiring developers to manage certificates or implement complex security code.
Perhaps most importantly, SPIFFE-based identity is portable. The same identity framework can work for services in Kubernetes, on EC2 instances, in on-premise data centers, or running as serverless functions. This universality makes SPIFFE particularly valuable in hybrid and multi-cloud environments where workloads need to authenticate across platform boundaries.
However, SPIFFE is not without its challenges. Setting up SPIFFE infrastructure requires significant upfront investment. You need to deploy and operate SPIRE servers, configure workload attestation for your various platforms, establish trust domains, and integrate SPIFFE identity into your applications – either directly or through a service mesh.
More critically, SPIFFE faces an adoption problem. While it’s excellent for authentication within your own infrastructure, most external APIs and third-party services don’t support SPIFFE. Stripe doesn’t accept SPIFFE SVIDs. Your database-as-a-service provider likely doesn’t either. This means that even organizations fully committed to SPIFFE internally must still manage traditional API keys and secrets for external integrations. You end up operating two parallel authentication systems: SPIFFE for your internal services and conventional secrets management for everything outside your trust domain.
Bridging the Gap
The evolution from static secrets to dynamic, cryptographically-verifiable workload identity represents more than just a technical improvement, it’s a fundamental shift in how we think about authentication. Rather than asking “does this caller possess the right secret?” we’re moving toward “is this caller the workload it claims to be, running in the right environment, with the appropriate permissions?”
The journey isn’t complete, however. Many systems still rely heavily on API keys and static secrets, and for good reason, they’re simple, well-understood, and work everywhere.
This is where platforms like Hush Security represent a pragmatic middle ground in this evolution. By internally managing SPIFFE-based workload attestation, Hush Security eliminates the operational complexity of running identity infrastructure while still providing cryptographic verification of workload identity. Once a workload’s identity is attested, the platform provides just-in-time secrets for accessing target resources, combining the universal compatibility of secrets with the security guarantees of verifiable identity.
The result is that the complete secret lifecycle, from creation to distribution to rotation, becomes invisible, and operators never manage SPIFFE infrastructure. The platform removes the security risk of long-lived static secrets, while maintaining compatibility with any secret-consuming service. It’s not about choosing between the old world and the new, it’s about using verifiable identity to make secrets ephemeral, scoped, and automatic.