Table of Contents
Zero Trust for AI agents is the right framework for this moment. Anthropic published their guide on it this month, and the thing I keep coming back to is how many of its controls rest on a single assumption: that you already have cryptographic, runtime identity for your agents and non-human workloads. Most organizations do not. That is the gap this post is about, and it is the gap Hush was built to close.
I want to say upfront that the guide is one of the best pieces of practical security writing I have seen on this topic. It is specific, grounded in real threats, and gives architects and engineers something actionable. If you build or secure AI-driven systems, read it. This post is my practitioner’s walkthrough, with a direct lens on where Hush fits into the implementation.
Why AI Agent Security Requires a New Zero Trust Approach
Most security frameworks describe what good looks like in theory. This one is grounded in what attacks already look like in practice. The opening observation alone is worth sitting with: frontier AI models are compressing the window between vulnerability and exploit from months to hours.
The framework introduces a design test worth applying to every control you currently have in place: does this make the attack impossible, or just tedious? Controls that work through friction, such as rate limits and non-standard ports, degrade significantly against an attacker operating at machine speed. I think that framing is exactly right.
Autonomous AI systems change the attack surface in ways traditional security models do not account for. Agents interpret natural language, invoke tools and MCP servers, maintain memory across sessions, and coordinate with other agents. A compromised MCP descriptor can silently redirect tool calls. A poisoned memory entry corrupts every session that follows. These are not hypothetical threats. The first malicious MCP server impersonating a legitimate email service, silently copying all outbound messages, was documented in the wild. The guide maps all of this carefully, and regulated industries in particular should pay attention: the framework aligns directly with HIPAA, FINRA, GDPR, and FedRAMP requirements that are already in force.
The Framework’s Design Test
When evaluating any control, ask: does this make the attack impossible, or just tedious? Controls whose value comes from friction degrade significantly against an adversary that can grind through tedious steps at scale.
Non-Human Identity Is the Foundation Zero Trust for AI Agents Requires
The guide structures recommendations across three tiers: Foundation, Enterprise, and Advanced.
Foundation requires unique cryptographic identifiers for every agent instance, appearing in all logs and access requests.
Enterprise adds certificate-based authentication with lifecycle management.
Advanced moves to hardware-backed identity with attestation.
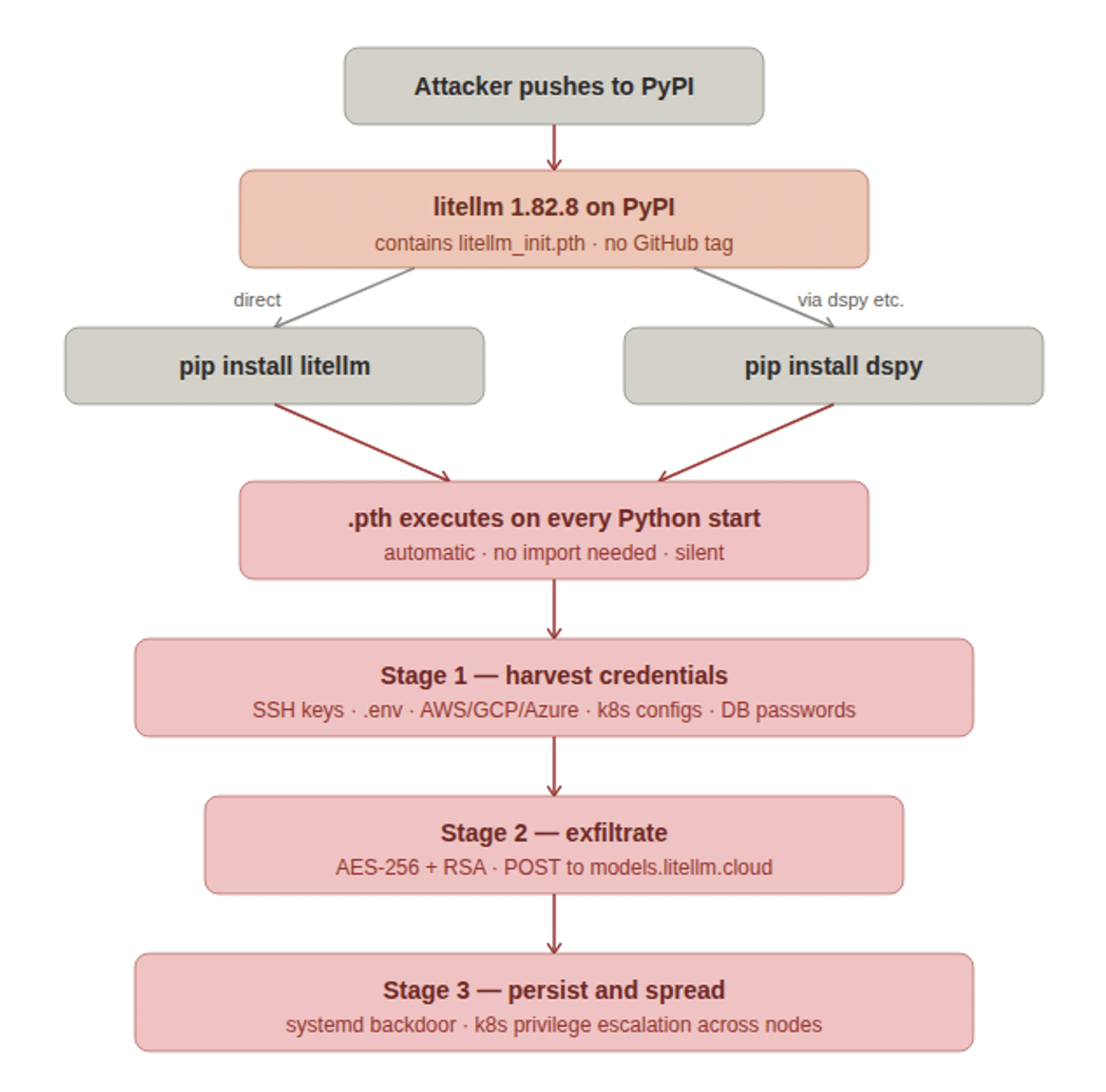
These tiers give teams a clear progression. Worth calling out directly: static API keys and embedded credentials are among the first things an attacker with model-assisted code analysis will find. The prescription is short-lived tokens issued by an identity provider, measured in minutes rather than days. That is exactly the model Hush is built around.
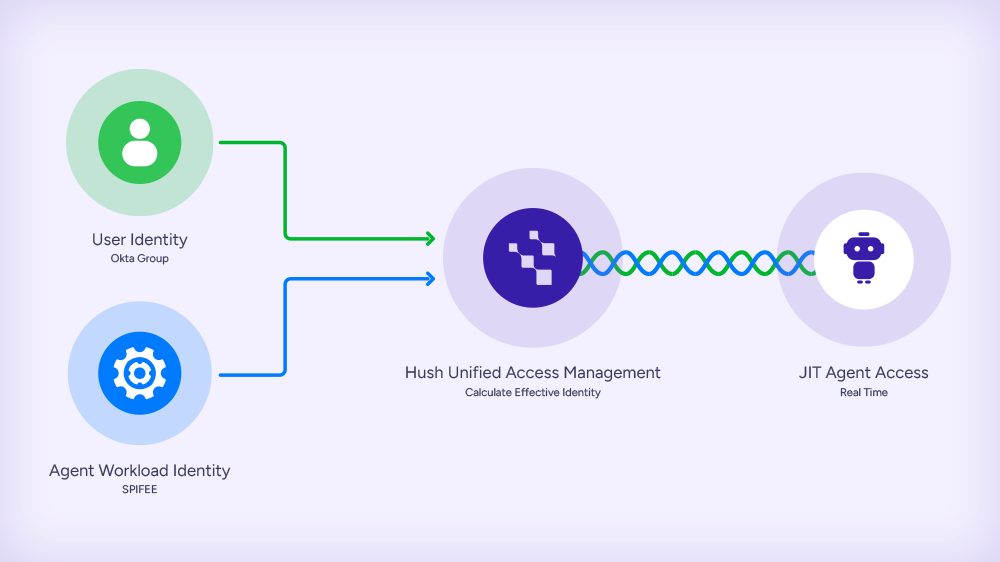
Hush issues credentials at the moment a workload needs access, scoped to the exact task, and expires them immediately after use. No long-lived secrets to rotate, audit, or accidentally expose. The SPIFFE framework underpins all of it, giving every workload and agent a verifiable runtime identity.
On the Framework’s Credential Guidance
Short-lived, narrowly-scoped tokens issued by an identity provider are the new baseline. Rotating a credential that can be found in a lockfile does not meaningfully raise the cost to an AI-assisted attacker.
Agent Identity Verification: How Hush Maps to Each Zero Trust Tier
The table below maps each identity and authentication requirement from the guide to the corresponding Hush capability.
| Tier | Framework Requirement | Hush Capability |
|---|---|---|
| Foundation | Unique cryptographic identifiers per agent instance; IDs appear in all logs and access requests. | Runtime discovery assigns persistent, cryptographically rooted identity to every workload, agent, and NHI. All telemetry is attributed to a specific identity automatically. |
| Enterprise | Certificate-based authentication with lifecycle management, rotation, and revocation. | Hush issues short-lived, just-in-time credentials at runtime and attest identity via the SPIFFE framework. Lifecycle is managed automatically. No manual rotation required. |
| Advanced | Hardware-backed identity stored in HSMs or TPMs. Remote attestation to verify agent integrity before granting access. Confidential computing enclaves for sensitive operations. | Hush operates on-premises and in hybrid environments, keeping credential issuance within the customer’s own infrastructure boundary. SPIFFE-based identity provides the cryptographic foundation that hardware-bound identity and attestation builds on. |
Least Agency: The Access Control Principle Built for AI Agents
One concept I think deserves wider adoption is Least Agency, a term coined by OWASP and highlighted throughout the Anthropic framework. Least privilege constrains what a system can access. Least Agency goes further: it restricts what each agent tool can do, how often, and from where. An email-drafting agent needs email permissions, not access to the finance file share.
This matters because most credential systems are not built to express task-scoped permissions at the agent level. Approved actions, prohibited actions, escalation triggers, and scope limits all need to be explicit and enforced at the access layer, not just declared in agent instructions.
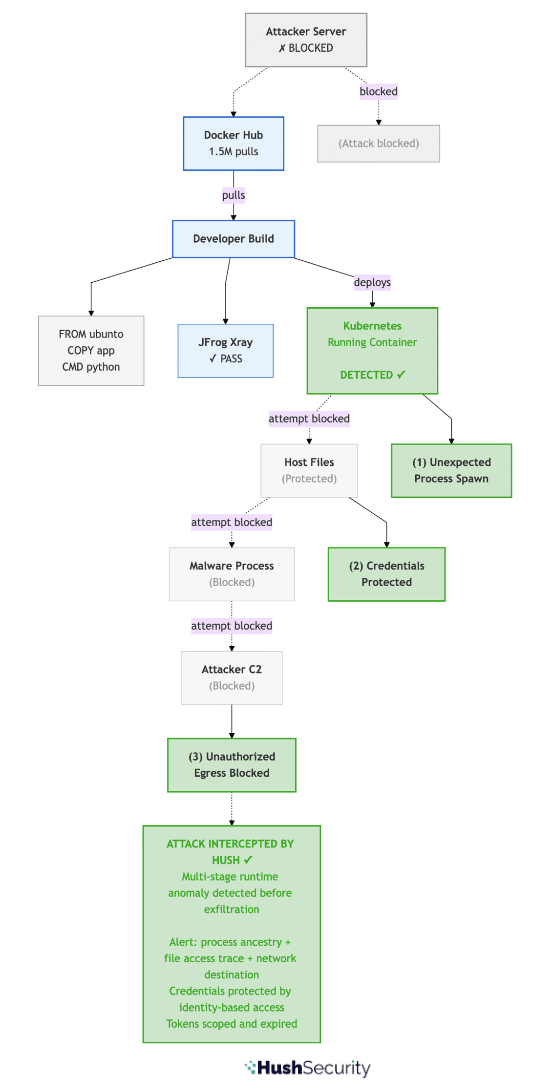
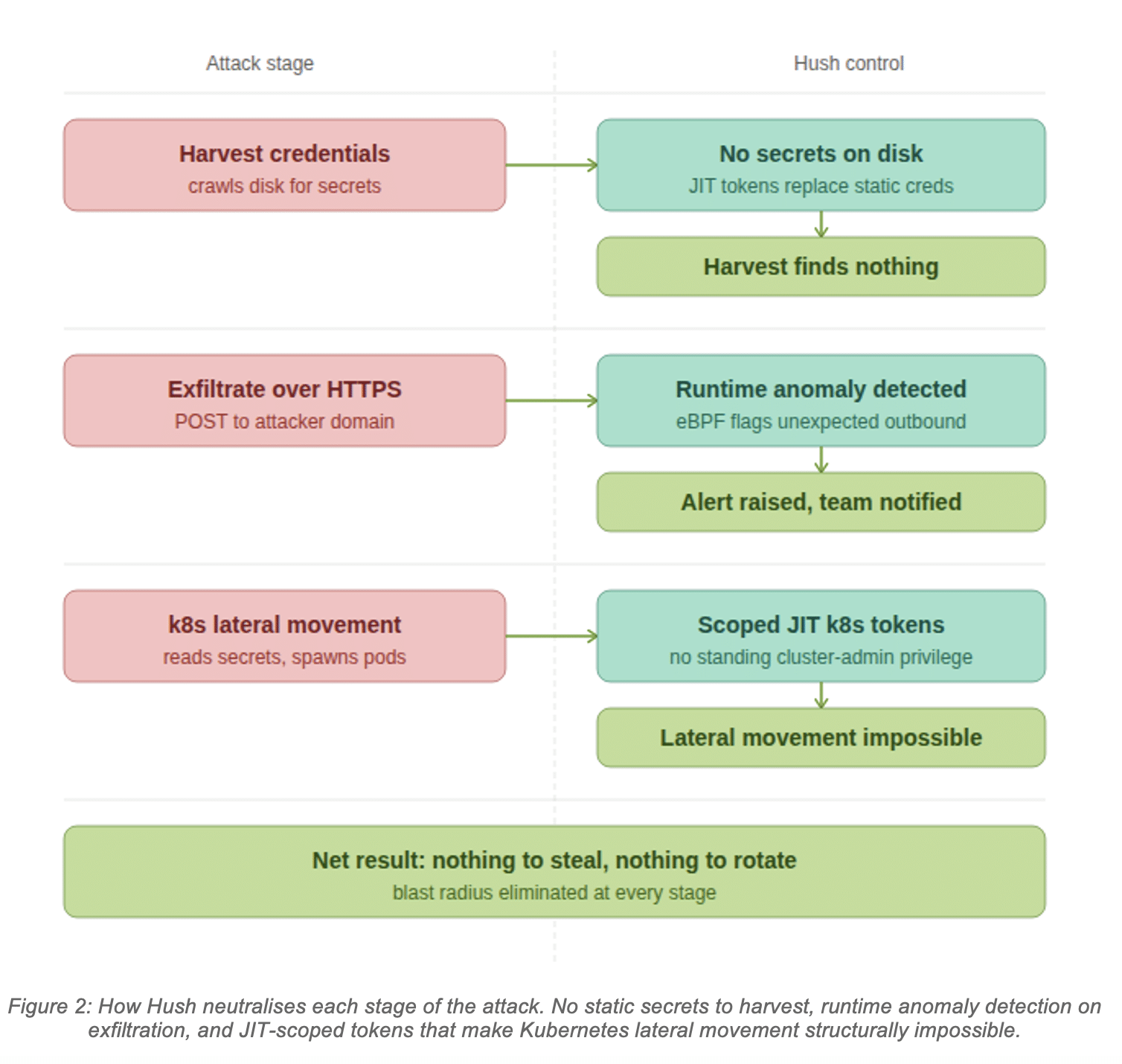
Hush enforces Least Agency through runtime policy. Machine-to-machine interactions are mapped continuously and converted into access policies that define exactly which workloads can reach which services. Any connection outside that policy is blocked at the point of access. The capabilities that deliver this:
- Runtime Visibility and Discovery: continuous discovery of every workload, service, and AI agent from code to production, including shadow credentials and NHIs not visible in static scans.
- Just-in-Time Scoped Access: credentials issued at the moment of access, scoped to the exact task, expired immediately after use. No standing access for agents to misuse.
- Runtime Posture Analysis: risks prioritized based on actual runtime behavior and blast radius, not static configuration.
- No Code or Application Changes: lightweight sensors run transparently in the background.
MCP Security and Supply Chain Risk for AI Agent Deployments
The framework’s section on MCP security and supply chain risk is one I recommend reading carefully. AI agent deployments compose capabilities at runtime, loading tools and personas dynamically from external sources. Traditional software composition analysis was not designed for this model, and the attack surface it creates is underappreciated.
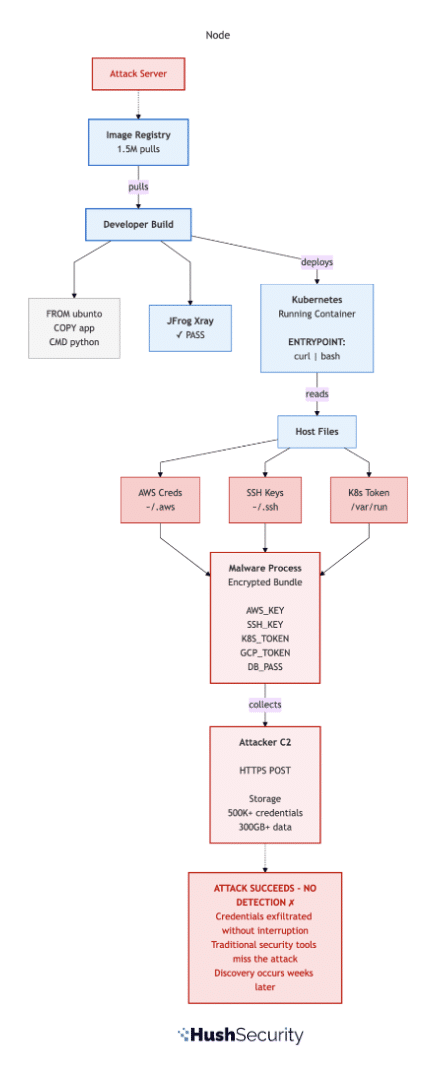
Tool chaining attacks illustrate why this is hard to catch. An attacker does not need to compromise a single high-privilege tool. Instead, they manipulate an agent into combining two legitimate, low-privilege tools in a sequence that exposes data neither would surface on its own. Every command runs through trusted binaries under valid credentials, so host-based monitoring has nothing to flag. The access looks correct because the credentials are legitimate.
Running MCP servers on immutable infrastructure after code verification, signing them cryptographically, and requiring identity-based authentication for every tool connection is the right prescription. Hush enforces this at the access layer: every connection from an agent to a tool or service is governed by a named policy. If a workload is not explicitly authorized to reach a given service, the connection does not happen, regardless of what instructions the agent received. That external enforcement, sitting outside the agent itself, is what makes the control reliable.
Runtime Visibility and Incident Investigation for Non-Human Identities
Two metrics matter most before any other detection investment: dwell time, meaning how long from an anomaly to human awareness, and coverage, meaning the fraction of alerts actually investigated. Both depend entirely on attribution. Without knowing which specific agent instance made a decision or accessed a resource, you cannot trace the chain of events that produced an incident. You can measure that something went wrong. You cannot explain how.
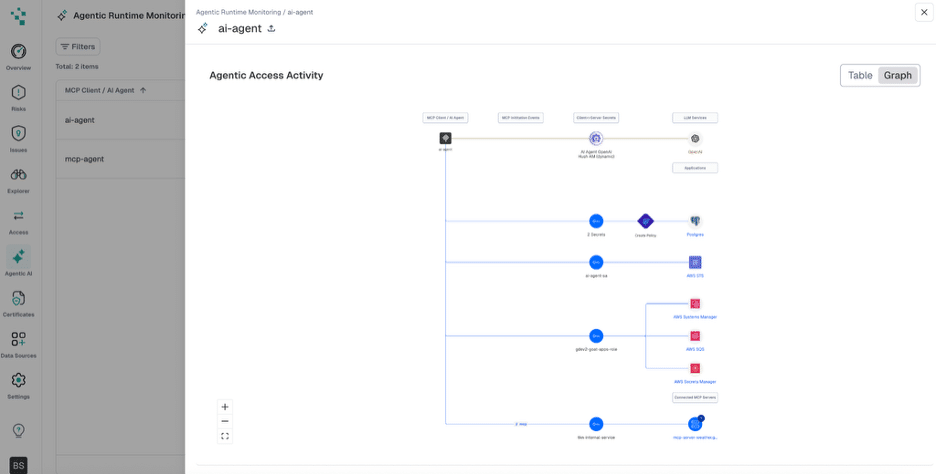
Hush provides runtime telemetry with identity attribution for every workload and agent action. Because Hush facilitates the access itself, every connection is logged against the verified identity that initiated it. The visual lineage map shows exactly which agents connect to which services, what credentials they use, and when, giving security teams the starting point they need to reconstruct an incident rather than beginning from a pile of unattributed events. For teams dealing with compliance requirements around algorithmic explainability, that audit trail is not optional.
Implementing Zero Trust for AI Agents: Four Concrete Steps
The guide recommends beginning at Foundation and advancing tiers as deployments scale. Here is how to sequence that with Hush.
Step 1: Discover Every Non-Human Identity at Runtime
You cannot govern what you cannot see, and most teams discover NHIs and agents they did not know existed once runtime discovery is in place. Hush’s free tier provides continuous discovery across cloud, on-premises, and hybrid environments, building an inventory based on real-world usage rather than configuration assumptions. The first time most teams run it, something unexpected shows up.
Step 2: Map Your Static Secrets and Credential Exposure
Static API keys and embedded credentials are easier to find than most teams expect, and they are the first thing an AI-assisted attacker looks for. Hush detects exposed, leaked, and misconfigured secrets across code, cloud, and pipelines, surfaced with blast-radius prioritization so you know what to fix first and what the consequences of each exposure would be.
Step 3: Define Explicit Access Policies for Each Agent
An agent with vague permission to ‘help with customer service’ has no enforceable boundaries. Approved actions, prohibited actions, and scope limits need to be written down and enforced at the access layer. Hush converts observed machine-to-machine interactions into access policies automatically, giving you a starting point grounded in how your agents actually behave rather than how you assume they do.
Step 4: Replace Static Credentials with JIT Scoped Access
Start with the workload carrying the largest blast radius. Hush provisions just-in-time, scoped credentials at runtime and enforces policy at the point of access, with no code changes or infrastructure redesign required. Once one workload is running under JIT access the pattern is established. Expansion to the rest of the fleet follows the same process.
The Identity Access Layer That Makes Zero Trust for AI Agents Practical
What I find most valuable about the Anthropic framework is that it does not let you off the hook with vague principles. The tier structure forces a real question: are you at Foundation, or are you below it? Most teams, when they look honestly at their agent deployments, find they are below it. Not because they made bad decisions, but because the identity and access infrastructure the framework assumes has not existed in a practical, deployable form until recently.
That is what Hush is built to change. The framework sets the destination. We give you the access layer to get there from day one, without a multi-year infrastructure overhaul standing in the way.
If you want to see how it works in practice, get started for free or schedule a demo with the team.